在使用MySql的时候,基本都是用图形化工具,如navicat。最近发现连最基本的创建表的语法都快忘了...
所以,想要重新系统性的学习下MySql,为后面学习MySql的一些高级查询,MySql性能和SQL语句的优化等打个基础。
用博客来记录下学习的过程,方便以后查阅和加强记忆。有错误的地方还请指出!
一、MySql的基本操作命令
注: <>表示参数、[]表示可选项
连接数据库:mysql> mysql -u<username> -p<password>;
显示所有数据库:mysql> show databases;
选择数据库:mysql> use <database name>;
创建一个数据库:mysql> create database <database name> [charset <charset>];
删除一个数据库:mysql> drop database <database name>;
修改数据库名:mysql无法直接修改数据库名!
显示所有表:mysql> show tables;
删除一张表:mysql> drop table <table name>;
修改表名:mysql> rename table <table name> to <new table name>;
清空表:mysql> truncate <table name>;
truncate和delete的区别:truncate相当于删表再重建一张相同结构的表,操作后得到一张全新表;delete只是删除数据,而且是按照行来删除,如果表中有自增型字段,其影响还在。
查看表结构:mysql> desc <table name>;
设置服务器编码(临时性的):mysql> set names <charset>;
注意对数据库进行操作时,保持编码的一致性,否则会导致一些不明不白的问题;
一般我们的doc窗口是gbk编码的,所以我们要告诉数据库服务器我们客户端使用的是gbk编码:set names gbk;这样我们插入的数据就会按照gbk来解码,否则轻微的乱码,严重的直接报错。
将SQL语句以日志形式记录到sql文件:tee <location>;

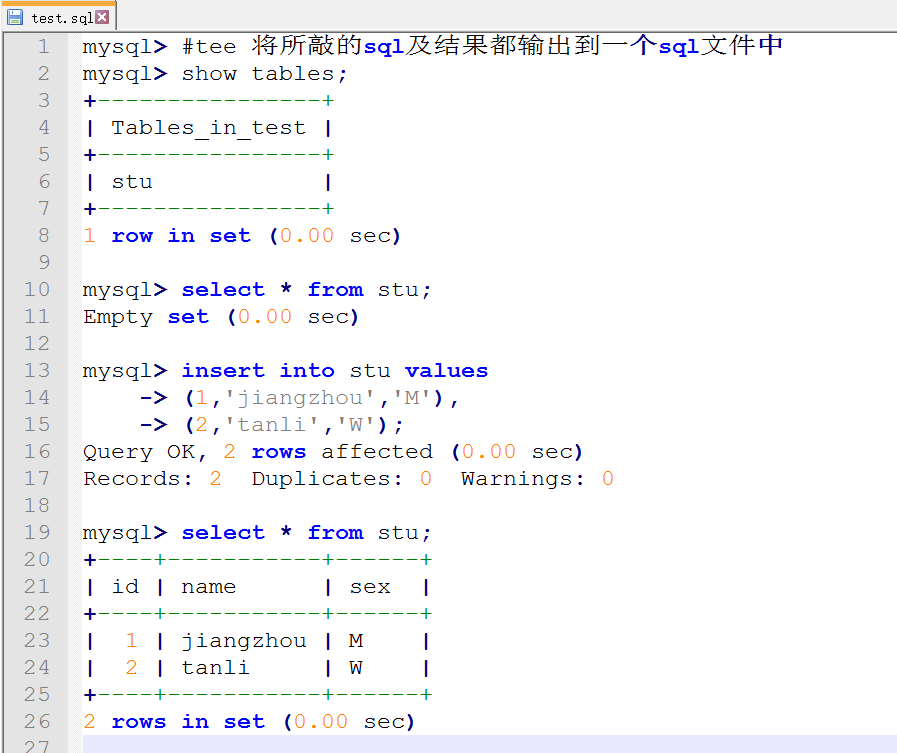
二、基本SQL语句
1.插入语句:
插入指定字段数据:mysql> insert into <table>(filed1,filed2,filed3...) values(v1,v2,v3...);

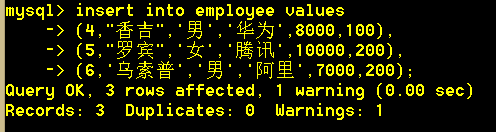
插入所有字段数据:mysql> insert into <table> values(v1,v2,v3...vn);
修改语句:mysql> update <table> set <filed1=v1> where <expression>;

删除语句:mysql> delete from <table> where <expression>;

删除所有数据:mysql> delete from <table>; 只是删除数据;
2.查询语句:
查询某些字段:mysql> select filed1, filed2,filed3 from <table> [where <expression>];
尽量不要使用select * from <table>,取出自己想要的行和列即可;
3.修改表
增加一列:mysql> alter table <table> add <field> <type> [other] ‘‘;
在某列后增加一列:mysql> alter table <table> add <field> <type> [other] after <field1>;
添加到第一列:mysql> alter table <table> add <field> <type> [other] first;
删除某一列:mysql> alter table <table> drop <field>;
修改某一列的参数:mysql> alter table <table> modify <field> <type> [other];
修改列名(必须带上参数):mysql> alter table <table> change <old field> <new field> <type> [other];
①.增加一列:mysql> alter table <table> add <field> <type> [other] ‘‘;

②.在某列后增加一列:mysql> alter table <table> add <field> <type> [other] after <field1>;

③.添加到第一列:mysql> alter table <table> add <field> <type> [other] first;

④.删除某一列:mysql> alter table <table> drop <field>;

⑤.修改某一列的参数:mysql> alter table <table> modify <field> <type> [other];

⑥.修改列名(必须带上参数):mysql> alter table <table> change <old field> <new field> <type> [other];

三、MySql三大列类型
推荐博客:MySQL 请选择合适的列!
1.数值型
整型:tinyint smallint mediuint int bigint
tinyint: 占一个字节8位(1byte=8bit),有符号为-128 - 127 (-2n-1 - 2n-1-1),无符号为0 - 255(0 - 2n-1); 有符号时,正数第一位为0,负数第一位为1; 负数=绝对值-128;
int系列(整型)的类型声明时的参数:(M) unsigned zerofill
#unsigned: 无符号类型;

#(M) + zerofill : M表示数据的宽度(不是大小), (M)参数必须和zerofill配合使用才有意义,不够位时用0填充,要配合zerofill使用才有效果,单独使用是没有意义的(如int(11));也就是说就算设置了int(20),也没有影响,除非使用zerofill。而且使用了zerofill后,建的字段默认就为unsigned,看第二张图。

#smallint(0 - 65535) 只能存5位数,却可以填充20个0....


小数型:浮点型/定点型
float(M,D),decimal(M,D)
float和decimal都是变长类型,要用多大,就分多大,不要无谓的分太大了。
① float(浮点)要么占4个字节,要么8个字节
M叫"精度" --> 代表"总位数",D代表"标度",代表小数位(小数点右边的位数)

#小数点后面超出位数则四舍五入:

#小数点左边是不能超出位数的:

float 能存 10^38 - 10^-38
如果M<=24,占4个字节,否则占8个字节
#float的精确度有时会有损失:所以对精确度要求高的数据是不能用float来存储的,如银行存钱!float在内部是用二进制表示的如:7.22用32位二进制是表示不了的,会被当做整型处理。所以就不精确了。

② decimal(定点):定点是把整数部分,和小数部分分开存储的,比float精确。

#测试小数位:说明小数位还是会被四舍五入的

#但是decimal的精确度比float高:decimal是将整数部分和小数部分分开存储的,所以比float精确。只是将最后一位进行了四舍五入

*银行存钱既不是用的float也不是decimal,是用整型来存储,钱会被换成分来存储;者不防也是一种好的设计方式。
*在指定decimal的精度时,也不是随便指定一个长度就行的,看下表:(此部分查看了一些博客,众说纷纭,可能不正确)
DECIMAL(18,9)使用9个字节,小数点前4个字节,小数点1个字节,小数点后4个字节;
DECIMAL(8,2)使用5个字节,小数点前3个字节(6位),小数点1个字节,小数点后1个字节。
DECIMAL(9,2)使用6个字节,小数点前4个字节(7位),小数点1个字节,小数点后1个字节。(所有小数点后一般存两位,小数点前要合理选择)
#下面是MySql手册的说法


区别:
1、FLOAT和DOUBLE支持标准浮点运算进行近似计算。
2、DECIMAL进行DECIMAL运算,CPU并不支持对它进行直接计算。浮点运算会快一点,因为计算直接在CPU上进行。
3、DECIMAL只是一个存储格式,在计算时会被转换为DOUBLE类型。
4、DECIMAL(18,9)使用9个字节,小数点前4个字节,小数点1个字节,小数点后4个字节。
5、DECIMAL只有对小数进行精确计算的时候才使用它,如保存金融数据。
2.字符串型
① char(M):定长类型(0 <= M <= 255 注意M是长度,不是字节数) 能存储固定M个长度,不足用空格补至M个
char类型的查询速度快,在查找行记录时,因为都是定长,完全可以通过行数和行的长度(即M)计算出文件指针的偏移量,所以查询速度快;
但是数据必须在限定的长度(M)范围内;char(M) 如果不够M个长度,会在末尾用空格补至M个长度,所以会存在浪费的情况。
#不能超出范围(严格模式下):

#char(M)如果不够M个长度,会在末尾用空格补齐,而取出数据的时候,会去掉右侧的空格,看测试:

② varchar(M):变长类型(0 <= M <= 65535 注意M是长度,不是字节数) 存储0-M个字符
*varchar(M)类型数据前会有一个前缀码,用于保存数据的长度,每次从磁盘文件中读取数据的时候,就是先读取这个前缀码的数值(比如2),然后文件指针往后偏移2个长度,读取出数据。
*varchar(M)类型数据如果不够M个长度,不会像char那样用空格补齐,但是varchar前面有1-2两个字节(因为varchar长度范围在0-65535,最多占两个字节)用来标志该列内容的长度。所以就算存储空数据,该列至少占一个字节。
注意char(M)和varchar(M)的M只代表字符长度,不代表字节数,不管是中文还是英文,都是长度;char和varchar类型占的字节跟使用的字符编码有关


③ text:变长类型,跟varchar类似[varchar(65535) = text ],会有1-4个字节用于存储文本长度值,blob同理。
四种类型:TINYTEXT、TEXT、MEDIUMTEXT和LONGTEXT
text类型, 可以存比较大的文本段,搜索速度稍慢;因此,如果不是特别大的内容,建议用char,varchar来代替
text不用加默认值,加了也没有用
④ blob
BLOB是一个二进制大对象,可以容纳可变数量的数据。有4种BLOB类型:TINYBLOB、BLOB、MEDIUMBLOB和LONGBLOB。它们只是可容纳值的最大长度不同。
blob一般用来存储图像、音频等二进制数据,也可以存文本类型。
blob的最大意义在于防止因为字符集的问题,导致信息丢失。比如:一张图片中有0xFF字节,这个在ASCII字符集中为非法,在入库的时候就会被过滤掉,但如果存成blob类型,就是以二进制形式存储,存进去的是什么,取出来的还是什么,数据不会丢失。
text和blob都不怎么常用,其存储的字符量大,查询速度稍慢。一般来说varchar足够。
#blob和text类型都不能设置默认值.

#但是是可以有非空约束的


⑤NCHAR、NVARCHAR、NTEXT。
这三种从名字上看比前面三种多了个“N”。它表示存储的是Unicod数据类型的字符。我们知道字符中,英文字符只需要一个字节存储就足够了,但汉字众多,需要两个字节存储,英文与汉字同时存在时容易造成混乱,Unicode字符集就是为了解决字符集这种不兼容的问题而产生的,它所有的字符都用两个字节表示,即英文字符也是用两个字节表示。nchar、nvarchar的长度是在1到4000之间。和char、varchar比较起来,nchar、nvarchar则最多存储4000个字符,不论是英文还是汉字;而char、varchar最多能存储8000个英文,4000个汉字。可以看出使用nchar、nvarchar数据类型时不用担心输入的字符是英文还是汉字,较为方便,但在存储英文时数量上有些损失。所以一般来说,如果含有中文字符,用nchar/nvarchar,如果纯英文和数字,用char/varchar。
3.日期时间类型
*可以使用任何常见格式指定DATE、DATETIME和TIMESTAMP值,‘YYYY-MM-DD HH:MM:SS‘或‘YY-MM-DD HH:MM:SS‘格式的字符串。
*允许“不严格”语法:任何标点符都可以用做日期部分或时间部分之间的间割符。例如,‘98-12-31 11:30:45‘、‘98.12.31 11+30+45‘、‘98/12/31 11*30*45‘和‘[email protected]@31 11^30^45‘是等价的。
*‘YYYYMMDDHHMMSS‘或‘YYMMDDHHMMSS‘格式的没有间割符的字符串,假定字符串对于日期类型是有意义的。例如,‘19970523091528‘和‘970523091528‘被解释为‘1997-05-23 09:15:28‘,但‘971122129015‘是不合法的(它有一个没有意义的分钟部分),将变为‘0000-00-00 00:00:00‘。

*包含两位年值的日期会令人模糊,因为世纪不知道。MySQL使用以下规则解释两位年值:
00-69范围的年值转换为2000-2069。
70-99范围的年值转换为1970-1999。

①date 日期 存储‘2016-09-04‘类型
MySQL用‘YYYY-MM-DD‘格式检索和显示DATE值。支持的范围是‘1000-01-01‘到 ‘9999-12-31‘。
#如果你为一个DATE对象分配一个DATETIME或TIMESTAMP值,结果值的时间部分被删除,因为DATE值未包含时间信息。

②time 时间
MySQL以‘HH:MM:SS‘格式检索和显示TIME值(或对于大的小时值采用‘HHH:MM:SS‘格式)。
TIME值的范围可以从‘-838:59:59‘到‘838:59:59‘。小时部分会如此大的原因是TIME类型不仅可以用于表示一天的时间(必须小于24小时),还可能为某个事件过去的时间或两个事件之间的时间间隔(可以大于24小时,或者甚至为负)。
#time不能随意指定连接符:‘HHMMSS‘、‘HH:MM:SS‘、‘HH:MM‘、‘D HH:MM:SS‘,这里D表示日,可以取0到34之间的值。无效TIME值被转换为‘00:00:00‘。

#可以看出,最终都变成HH:MM:SS格式了;D表示日,在当前小时基础上加上D天;CURRENT_TIME函数用于获取当前时间

③datetime
MySQL以‘YYYY-MM-DD HH:MM:SS‘格式检索和显示DATETIME值。支持的范围为‘1000-01-01 00:00:00‘到‘9999-12-31 23:59:59‘。
datetime即date跟time的组合,参照上面。
④year 年
YEAR类型是一个单字节类型用于表示年。MySQL以YYYY格式检索和显示YEAR值。范围是1901到2155。非法YEAR值被转换为0000。
说明下year是如何用一个字节存储1901-2155的,一个无符号字节能存0-255,即266种变化,year的基数是1900年,从1-255 》 1901-2155,再加一种0000即为266种年份,所以year占用的一个字节是这样使用的。
两位长度,范围为‘00‘到‘99‘。‘00‘到‘69‘和‘70‘到‘99‘范围的值被转换为2000到2069和1970到1999范围的YEAR值。
⑤timestamp 时间戳
TIMESTAMP列的显示格式与DATETIME列相同。换句话说,显示宽度固定在19字符,并且格式为YYYY-MM-DD HH:MM:SS。
特性:
在CREATE TABLE语句中,可以用下面的任何一种方式声明第1个TIMESTAMP列:(注意是第一个timestamp列,其它列会有所区别,见MySql手册)
用DEFAULT CURRENT_TIMESTAMP和ON UPDATE CURRENT_TIMESTAMP子句,列为默认值使用当前的时间戳,并且自动更新。
不使用DEFAULT或ON UPDATE子句,与DEFAULT CURRENT_TIMESTAMP ON UPDATECURRENT_TIMESTAMP相同。
用DEFAULT CURRENT_TIMESTAMP子句不用ON UPDATE子句,列为默认值使用当前的时间戳但是不自动更新。
不用DEFAULT子句但用ON UPDATE CURRENT_TIMESTAMP子句,列有默认值0并自动更新。
用常量DEFAULT值,列有给出的 默认值。如果列有一个ON UPDATE CURRENT_TIMESTAMP子句,它自动更新,否则不。
换句话说,你可以为初始值和自动更新的值使用当前的时间戳,或者其中一个使用,或者两个皆不使用。
#不使用DEFAULT或ON UPDATE子句,与DEFAULT CURRENT_TIMESTAMP ON UPDATECURRENT_TIMESTAMP相同。

#使用默认插入当前时间:(用DEFAULT CURRENT_TIMESTAMP子句不用ON UPDATE子句,列为默认值使用当前的时间戳但是不自动更新。)

#使用默认值和自动更新:(用DEFAULT CURRENT_TIMESTAMP和ON UPDATE CURRENT_TIMESTAMP子句,列为默认值使用当前的时间戳,并且自动更新。)

#虽然我们也可以用char(M),或varchar(M)来存储日期/时间,比如char(19)来存储YYYY-MM-DD HH:MM:SS‘‘datetime类型;也许会认为char查询速度快,刚好占用19个字节,也不会浪费空间;但其实不是这样的;我们最好专列专用,存什么类型的数据就用什么类型,存日期就用日期类型,MySql是对其做了优化的,效率高,存储空间利用高,而且我们也会给我们后面的解析造成一定影响,多做些工作。根据某些需求,我们可以用int来存储时间戳,以提高效率。
#从下表可以看出,用datetime只占了8个字节,char(19)占了19个字节。

四、MySql建表
建表的过程就是一个声明列的过程;
建表的时候,不防让所有列都为定长,这样每行数据也都是定长,可以极大的提高查询速度。如果在一张表中,只有一两列是变长类型,其余都是定长类型,虽然能节省一点空间,但查询速度会下降几个数量级,岂不是很可惜,在不浪费太多空间的前提下,尽量以空间换时间。
在计算机的优化中,空间与时间是一对矛盾,优化无非就是:时间换空间、空间换时间。
一般来说对于字符长度较大的列[如varchar(1500), text],其数据也不会经常变动,我们可以将该列单独拿到一个表中,使用外键关联起来。
在开发中,我们把频繁用到的数据最好使用定长,存到主表,优先考虑效率;不经常用到和比较占用空间的数据如个人介绍等长文本数据存到另一种表中(辅助表),关联起来,主要考虑空间。
选择数据类型的原则:
1、更小通常更好。使用最小的数据类型。——更少的磁盘空间,内存和CPU缓存。而且需要的CPU的周期也更少。
2、简单就好。整数代价小于字符。——因为字符集和排序规则使字符比较更复杂。
3、尽量避免NULL ——如果计划对列进行索引,尽量避免把列设置为NULL。尽可能把字段定义为NOT NULL。——可以放置一个默认值,如‘’,0,特殊字符串。
原因:
(1)MYSQL难以优化NULL列。NULL列会使索引,索引统计和值更加复杂。
(2)NULL列需要更多的存储空间,还需要在MYSQL内部进行特殊处理。
(3)NULL列加索引,每条记录都需要一个额外的字节,还导致MyISAM中固定大小的索引变成可变大小的索引。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
MySql基础篇基本完了,算是复习完了,接下来会专门学习查询语句!