## MapReduce概述
- Google MapReduce的克隆版本
- 优点:海量数据的离线处理,易开发,易运行
- 缺点:实时流式计算
Hadoop MapReduce是一个软件框架,用于轻松编写应用程序,以可靠,容错的方式在大型集群(数千个节点)的商用硬件上并行处理大量数据(多TB数据集)
## MapReduce编程模型
**思想:分而治之**
MapReduce作业通常将输入数据集拆分为独立的块,这些块由map任务以完全并行的方式处理。框架对map的输出进行排序,然后输入到reduce任务。通常,作业的输入和输出都存储在文件系统中。该框架负责调度任务,监视它们并重新执行失败的任务。
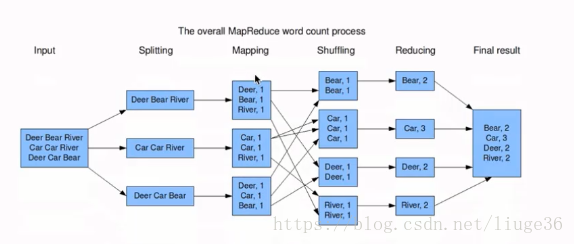
案例;统计一篇文章,各个单词出现的次数
Input数据输入
Splitting:拆分数据读取到各个节点
Mapping:为每一个单词赋1,不会做合并操作
Shuffling: 重新洗牌(指定规则),这里把相同单词发到同一个节点去
Reducing : 统计合并相同单词的次数
最后把结果写到一个文件中去就ok了
原文地址:https://www.cnblogs.com/liuge36/p/9881778.html
时间: 2024-10-10 00:06:13