对于简单的分析程序,我们只需一个MapReduce就能搞定,然而对于比较复杂的分析程序,我们可能需要多个Job或者多个Map或者Reduce进行计算。下面我们来说说多个Job或者多个MapReduce的编程形式
MapReduce的主要有以下几种编程形式
1、迭代式MapReduce
MapReduce迭代方式,通常是将上一个MapReduce任务的输出作为下一个MapReduce任务的输入,可只保留MapReduce任务的最终结果,中间数据可以删除或保留,如下所示

迭代式MapReduce的示例代码如下所示
/**
* @ProjectName MapReduceLinkJob
* @PackageName com.buaa
* @ClassName IterativeJob
* @Description TODO
* @Author 刘吉超
* @Date 2016-06-11 11:01:57
*/
public class IterativeJob extends Configured implements Tool {
// 这里只给出主要代码,其他省略
......
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
// 第一个MapReduce任务
Job job1 = new Job(conf,"job1");
...
// job1的输入
FileInputFormat.addInputPath(job1,input);
// job1的输出
FileOutputFromat.setOutputPath(job1,out1);
job1.waitForCompletion(true);
// 第二个Mapreduce任务
Job job2 = new Job(conf,"job2");
...
// job1的输出作为job2的输入
FileInputFormat.addInputPath(job2,out1);
// job2 的输出
FileOutputFromat.setOutputPath(job2,out2);
job2.waitForCompletion(true);
// 第三个Mapreduce任务
Job job3 = new Job(conf,"job3");
...
// job2的输出作为job3的输入
FileInputFormat.addInputPath(job3,out2);
// job3 的输出
FileOutputFromat.setOutputPath(job3,out3);
job3.waitForCompletion(true);
...
}
......
}
虽然MapReduce的迭代可实现多任务的执行,但是它具有如下两个缺点:
1、每次迭代,如果所有Job对象重复创建,代价将非常高。
2、每次迭代,数据都要写入本地,然后从本地读取,I/O和网络传输的代价比较大
2、依赖式MapReuce
依赖式MapReduce是由org.apache.hadoop.mapred.jobcontrol包中的JobControl类来实现。JobControl的实例表示一个作业的运行图,你可以加入作业配置,然后告知JobControl实例作业之间的依赖关系。在一个线程中运行JobControl时,它将按照依赖顺序来执行这些作业。也可以查看进程,在作业结束后,可以查询作业的所有状态和每个失败相关的错误信息。如果一个作业失败,JobControl将不执行与之有依赖关系的后续作业

依赖关系式MapReuce的示例代码如下所示
/**
* @ProjectName MapReduceLinkJob
* @PackageName com.buaa
* @ClassName DependentJob
* @Description TODO
* @Author 刘吉超
* @Date 2016-06-11 11:12:45
*/
public class DependentJob extends Configured implements Tool {
// 这里只给出主要代码,其他省略
......
@Override
public int run(String[] args) throws Exception {
Configuration conf1 = new Configuration();
Job job1 = new Job(conf1,"Job1");
...
Configuration conf2 = new Configuration();
Job job2 = new Job(conf2,"Job2");
....
Configuration conf3 = new Configuration();
Job job3 = new Job(conf3,"Job3");
....
// 构造一个ControlledJob
ControlledJob cJob1 = new ControlledJob(conf1);
// 设置ControlledJob
cJob1.setJob(job1);
ControlledJob cJob2 = new ControlledJob(conf2);
cJob2.setJob(job2);
ControlledJob cJob3 = new ControlledJob(conf3);
cJob2.setJob(job3);
// 设置job3和job1的依赖关系
job3.addDepending(job1);
// 设置job3和job2的依赖关系
job3.addDepending(job2);
JobControl JC = new JobControl("dependentJob");
// 把三个构造的ControlledJob加入到JobControl中
JC.addJob(cJob1);
JC.addJob(cJob2);
JC.addJob(cJob3);
Thread t = new Thread(JC);
t.start();
while (true) {
if (jobControl.allFinished()) {
jobControl.stop();
break;
}
}
}
......
}
注意:hadoop的JobControl类实现了线程Runnable接口。我们需要实例化一个线程来启动它。直接调用JobControl的run()方法,线程将无法结束。
3、链式MapReduce
大量的数据处理任务涉及对记录的预处理和后处理。例如:在处理信息检索的文档时,可能需要先移除stop words(像a、the和is这样经常出现但不太有意义的词),然后再做stemming(转换一个词的不同形式为相同的形式,例如转换finishing和finished为finish)。
我们可以为预处理与后处理各自编写一个MapReduce作业,并把它们链接起来。在这些作业中可以使用IdentityReducer(或完全不同的Reducer)。由于在执行过程中每一个作业的中间结果都需要占用I/O和存储资源,所以这种做法是低效的。另一种方法是自己写mapper去预先调用所有的预处理作业,再让reducer调用所有的后处理作业。这将强制我们采用模块化和可组合的方式来构建预处理和后处理。因此Hadoop引入了ChainMapper和ChainReducer类来简化预处理和后处理的构成。
hadoop提供了专门的链式ChainMapper和ChainReducer来处理链式MapReduce任务。在Map或者Reduce阶段存在多个Mapper,这些Mapper像Linux管道一样,前一个Mapper的输出结果直接重定向到后一个Mapper的输入,形成流水线,如下图所示
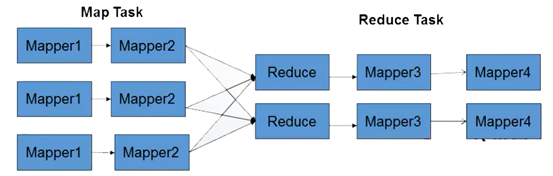
其调用形式如下:
... ChainMapper.addMapper(...); ChainReducer.setReducer(...); ChainReducer.addMapper(...); ...
addMapper方法如下:
public static void addMapper(Job job, Class<extends Mapper> mclass, Class<extends K1> inputKeyClass, Class<extends V1> inputValueClass, Class<extends K2> outputKeyClass, Class<extends V2> outputValueClass, Configuration conf )
addMapper()方法有8个参数。第一个和最后一个分别为全局的Job和本地的configuration对象。第二个参数是Mapper类,负责数据处理。余下4个参数 inputKeyClass、inputValueClass、outputKeyClass和outputValueClass是这个Mapper类中输入/输出类的类型。ChainReducer专门提供了一个setReducer()方法来设置整个作业唯一的Reducer,语法与addMapper()方法类似。
链式MapReduce的示例代码如下所示
/**
* @ProjectName MapReduceLinkJob
* @PackageName com.buaa
* @ClassName ChainJob
* @Description TODO
* @Author 刘吉超
* @Date 2016-06-11 11:16:55
*/
public class ChainJob extends Configured implements Tool {
// 这里只给出主要代码,其他省略
......
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJobName("chainjob");
job.setInputFormat(TextInputFormat.class);
job.setOutputFormat(TextOutputFormat.class);
FileInputFormat.addInputPath(job, in);
FileOutputFormat.setOutputPath(job, out);
// 在作业中添加 Map1 阶段
Configuration map1conf = new Configuration(false);
ChainMapper.addMapper(job, Map1.class, LongWritable.class, Text.class,Text.class, Text.class, map1conf);
// 在作业中添加 Map2 阶段
Configuration map2conf = new Configuration(false);
ChainMapper.addMapper(job, Map2.class, Text.class, Text.class,LongWritable.class, Text.class, map2conf);
// 在作业中添加 Reduce 阶段
Configuration reduceconf = new Configuration(false);
ChainReducer.setReducer(job,Reduce.class,LongWritable.class,Text.class,Text.class,Text.class ,reduceconf);
// 在作业中添加 Map3 阶段
Configuration map3conf = new Configuration(false);
ChainReducer.addMapper(job,Map3.class,Text.class,Text.class,LongWritable.class,Text.class ,map3conf);
// 在作业中添加 Map4 阶段
Configuration map4conf = new Configuration(false);
ChainReducer.addMapper(job,Map4.class,LongWritable.class,Text.class,LongWritable.class,Text.class ,map4conf);
job.waitForCompletion(true);
}
......
}
注意:对于任意一个MapReduce作业,Map和Reduce阶段可以有无限个Mapper,但是Reduce只能有一个。所以包含多个Reduce的作业,不能使用ChainMapper/ChainReduce来完成。
如果,您认为阅读这篇博客让您有些收获,不妨【顶】一下
如果,您希望更容易地发现我的新博客,不妨【订阅】
如果,您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是【刘超-ljc】。
本文版权归作者和csdn共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。