一 故障指南
1.1 常见问题排障
为了跟踪和发现在Kubernetes集群中运行的容器应用出现的问题,常用如下查错方法:
- 查看Kubernetes对象的当前运行时信息,特别是与对象关联的Event事件。这些事件记录了相关主题、发生时间、最近发生时间、发生次数及事件原因等,对排查故障非常有价值。此外,通过查看对象的运行时数据,还可以发现参数错误、关联错误、状态异常等明显问题。由于在Kubernetes中多种对象相互关联,因此这一步可能会涉及多个相关对象的排查问题。
- 对于服务、容器方面的问题,可能需要深入容器内部进行故障诊断,此时可以通过查看容器的运行日志来定位具体问题。
- 对于某些复杂问题,例如Pod调度这种全局性的问题,可能需要结合集群中每个节点上的Kubernetes服务日志来排查。比如搜集Master上的kube-apiserver、kube-schedule、kube-controler-manager服务日志,以及各个Node上的kubelet、kube-proxy服务日志,通过综合判断各种信息,就能找到问题的成因并解决问题。
二 常见措施
2.1 查看Event
[[email protected] ~]# kubectl describe pod kibana-logging-7dcbbd96d6-tsr82 -n kube-system

解读:通过kubectl describe pod命令,可以显示Pod创建时的配置定义、状态等信息,还可以显示与该Pod相关的最近的Event事件,事件信息对于查错非常有用。如果某个Pod一直处于Pending状态,可以通过kubectl describe命令了解具体原因。
通常,从Event事件中获知Pod失败的原因可能有以下几种:
- 没有可用的Node以供调度。
- 开启了资源配额管理, 但在当前调度的目标节点上资源不足。
- 镜像下载失败。
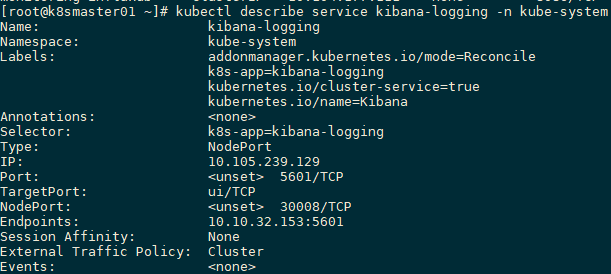
通过kubectl describe命令,还可以查看其他Kubernetes对象,包括Node、RC、Service、Namespace、Secrets等,对每种对象都会显示相关的其他信息。
[[email protected] ~]# kubectl describe service kibana-logging -n kube-system
2.2 查看日志
[[email protected] ~]# kubectl logs elasticsearch-logging-0 -n kube-system
[[email protected] ~]# kubectl logs elasticsearch-logging-0 -c elasticsearch-logging -n kube-system
解读:如上查看日志等同于在Pod的宿主机上运行docker logs <container_id>。容器中应用程序生成的日志与容器的生命周期是一致的,所以在容
器被销毁之后,容器内部的文件也会被丢弃,包括日志等。如果需要保留容器内应用程序生成的日志,则可以使用挂载的Volume将容器内应用程序生成的日志保存到宿主机,还可以通过一些工具如Fluentd、Elasticsearch等对日志进行采集。
2.3 查看Kubernetes服务日志
如果在Linux系统上安装Kubernetes,并且使用systemd系统管理Kubernetes服务,那么systemd的journal系统会接管服务程序的输出日志。 在此类环境中,可以通过使用systemd status或journalctl工具来查看系统服务的日志。
[[email protected] ~]# systemctl status kube-controller-manager.service -l

[[email protected] ~]# journalctl -u kube-controller-manager.service
如果不使用systemd系统接管Kubernetes服务的标准输出(如使用kubeadm部署的Kubernetes),则也可以通过日志相关的启动参数来指定日志的存放目录。
- --logtostderr=false:不输出到stderr。
- --log-dir=/var/log/kubernetes:日志的存放目录。
- --alsologtostderr=false:将其设置为true时,表示将日志同时输出到文件和stderr。
- --v=0:glog的日志级别。
- --vmodule=gfs*=2,test*=4:glog基于模块的详细日志级别。
在--log_dir设置的目录下可以查看各服务进程生成的日志文件,日志文件的数量和大小依赖于日志级别的设置。例如,kube-controller manager可能生成的几个日志文件如下:
- kube-controller-manager.ERROR;
- kube-controller-manager.INFO;
- kube-controller-manager.WARNING;
- kube-controller-manager.kubernetesmaster.unknownuser.log.ERROR.20150930-173939.9847;
- kube-controller-manager.kubernetesmaster.unknownuser.log.INFO.20150930-173939.9847;
- kube-controller-manager.kubernetesmaster.unknownuser.log.WARNING.20150930-173939.9847。
2.4 Kubernetes异常排查思路
通常可以从WARNING和ERROR级别的日志中就能找到问题的成因,但有时还需要排查INFO级别的日志甚至DEBUG级别的详细日志。
此外,etcd服务也属于Kubernetes集群的重要组成部分,etcd的日志同样重要。如果某个Kubernetes对象存在问题,则可以用这个对象的名字作为关键字搜索Kubernetes的日志来发现和解决问题。
通常Kubernetes主要是与Pod对象相关的问题,比如无法创建Pod、Pod启动后就停止或者Pod副本无法增加,等等。此时,可以先确定Pod在哪个节点上,然后登录这个节点,从kubelet的日志中查询该Pod的完整日志,然后进行问题排查。
对于与Pod扩容相关或者与RC相关的问题,则很可能在kube-controller-manager及kube-scheduler的日志中找出问题的关键点。
另外,若kube-proxy意外停止,Pod的状态也是正常的,但会导致某些服务访问异常。这些错误通常与每个节点上的kube-proxy服务有着密切的关系。遇到这些问题时,首先要排查kube-proxy服务的日志,同时排查防火墙服务,要特别留意在防火墙中是否有人为添加的可疑规则。
三 常见Kubernetes问题
3.1 无法pull镜像
由于无法下载pause镜像导致Pod一直处于Pending状态,可通过kubectl get pods命令查看。
解决方法如下。
- 如果服务器可以访问Internet,并且不希望使用HTTPS的安全机制来访问gcr.io,则可以在Docker Daemon的启动参数中加上--insecure-registry gcr.io,来表示可以匿名下载。
- 如果Kubernetes集群在内网环境中无法访问gcr.io网站,则可以先通过一台能够访问gcr.io的机器下载pause镜像,将pause镜像导出后,再导入内网的Docker私有镜像库,并在kubelet的启动参数中加上--pod_infra_container_image,配置为:--pod_infra_container_image=<docker_registry_ip>:<port>/pause:3.1,之后重新创建redis-master即可正确启动Pod。
注意:除了pause镜像,其他Docker镜像也可能存在无法下载的情况,与上述情况类似,很可能也是网络配置使得镜像无法下载,解决方法同上。
3.2 一直RESTARTS
创建一个RC之后,通过kubectl get pods命令查看Pod,发现Pod一会儿是Running状态,一会儿是ExitCode:0状态,在READY列中始终无法变成1/1,而且RESTARTS(重启的数量)的数量不断增加。这通常是因为容器的启动命令不能保持在前台运行。
在Kubernetes中根据RC定义创建Pod,之后启动容器。在容器的启动命令执行完成时,认为该容器的运行已经结束,并且是成功结束(ExitCode=0)的。根据Pod的默认重启策略定义(RestartPolicy=Always),RC将启动这个容器。新的容器在执行启动命令后仍然会成功结束,之后RC会再次重启该容器,如此往复。其解决方法为将Docker镜像的启动命令设置为一个前台运行的命令。
3.3 通过服务名无法访问
在Kubernetes集群中应尽量使用服务名访问正在运行的微服务,但有时会访问失败。由于服务涉及服务名的DNS域名解析、kube-proxy组件的负载分发、后端Pod列表的状态等,所以可通过以下几方面排查问题。
- 查看Service的后端Endpoint是否正常
可以通过kubectl get endpoints <service_name>命令查看某个服务的后端Endpoint列表,如果列表为空,则可能因为:
- Service的LabelSelector与Pod的Label不匹配;
- 后端Pod一直没有达到Ready状态(通过kubectlgetpods进一步查看Pod的状态);
- Service的targetPort端口号与Pod的containerPort不一致等。
- 查看Service的名称能否被正确解析为ClusterIP地址
可以通过在客户端容器中ping <service_name>.<namespace>.svc进行检查,如果能够得到Service的ClusterIP地址,则说明DNS服务能够正确解析Service的名称;如果不能得到Service的ClusterIP地址,则可能是因为Kubernetes集群的DNS服务工作异常。
- 查看kube-proxy的转发规则是否正确
可以将kube-proxy服务设置为IPVS或iptables负载分发模式。
对于IPVS负载分发模式,可以通过ipvsadm工具查看Node上的IPVS规则,查看是否正确设置Service ClusterIP的相关规则。对于iptables负载分发模式,可以通过查看Node上的iptables规则,查看是否正确设置Service ClusterIP的相关规则。
原文地址:https://www.cnblogs.com/itzgr/p/12684849.html