RDD的转换和DAG的生成
Spark会根据用户提交的计算逻辑中的RDD的转换和动作来生成RDD之间的依赖关系,同时这个计算链也就生成了逻辑上的DAG。接下来以“Word Count”为例,详细描述这个DAG生成的实现过程。
Spark Scala版本的Word Count程序如下:
1: val file = spark.textFile("hdfs://...")
2: val counts = file.flatMap(line => line.split(" "))
3: .map(word => (word, 1))
4: .reduceByKey(_ + _)
5: counts.saveAsTextFile("hdfs://...")
file和counts都是RDD,其中file是从HDFS上读取文件并创建了RDD,而counts是在file的基础上通过flatMap、map和reduceByKey这三个RDD转换生成的。最后,counts调用了动作saveAsTextFile,用户的计算逻辑就从这里开始提交的集群进行计算。那么上面这5行代码的具体实现是什么呢?
1)行1:spark是org.apache.spark.SparkContext的实例,它是用户程序和Spark的交互接口。spark会负责连接到集群管理者,并根据用户设置或者系统默认设置来申请计算资源,完成RDD的创建等。
spark.textFile("hdfs://...")就完成了一个org.apache.spark.rdd.HadoopRDD的创建,并且完成了一次RDD的转换:通过map转换到一个org.apache.spark.rdd.MapPartitions-RDD。
也就是说,file实际上是一个MapPartitionsRDD,它保存了文件的所有行的数据内容。
2)行2:将file中的所有行的内容,以空格分隔为单词的列表,然后将这个按照行构成的单词列表合并为一个列表。最后,以每个单词为元素的列表被保存到MapPartitionsRDD。
3)行3:将第2步生成的MapPartitionsRDD再次经过map将每个单词word转为(word, 1)的元组。这些元组最终被放到一个MapPartitionsRDD中。
4)行4:首先会生成一个MapPartitionsRDD,起到map端combiner的作用;然后会生成一个ShuffledRDD,它从上一个RDD的输出读取数据,作为reducer的开始;最后,还会生成一个MapPartitionsRDD,起到reducer端reduce的作用。
5)行5:首先会生成一个MapPartitionsRDD,这个RDD会通过调用org.apache.spark.rdd.PairRDDFunctions#saveAsHadoopDataset向HDFS输出RDD的数据内容。最后,调用org.apache.spark.SparkContext#runJob向集群提交这个计算任务。
RDD之间的关系可以从两个维度来理解:一个是RDD是从哪些RDD转换而来,也就是RDD的parent RDD(s)是什么;还有就是依赖于parent RDD(s)的哪些Partition(s)。这个关系,就是RDD之间的依赖,org.apache.spark.Dependency。根据依赖于parent RDD(s)的Partitions的不同情况,Spark将这种依赖分为两种,一种是宽依赖,一种是窄依赖。
RDD的依赖关系
RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。
1)窄依赖指的是每一个parent RDD的Partition最多被子RDD的一个Partition使用,如图1所示。
2)宽依赖指的是多个子RDD的Partition会依赖同一个parent RDD的Partition,如图2所示。
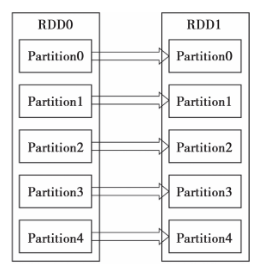
图 1 RDD的窄依赖
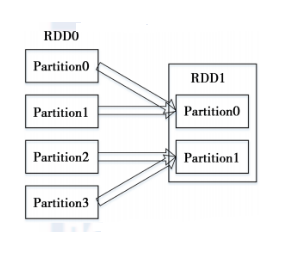
图 2 RDD的宽依赖
接下来可以从不同类型的转换来进一步理解RDD的窄依赖和宽依赖的区别,如图3所示。
对于map和filter形式的转换来说,它们只是将Partition的数据根据转换的规则进行转化,并不涉及其他的处理,可以简单地认为只是将数据从一个形式转换到另一个形式。对于union,只是将多个RDD合并成一个,parent RDD的Partition(s)不会有任何的变化,可以认为只是把parent RDD的Partition(s)简单进行复制与合并。对于join,如果每个Partition仅仅和已知的、特定的Partition进行join,那么这个依赖关系也是窄依赖。对于这种有规则的数据的join,并不会引入昂贵的Shuffle。对于窄依赖,由于RDD每个Partition依赖固定数量的parent RDD(s)的Partition(s),因此可以通过一个计算任务来处理这些Partition,并且这些Partition相互独立,这些计算任务也就可以并行执行了。
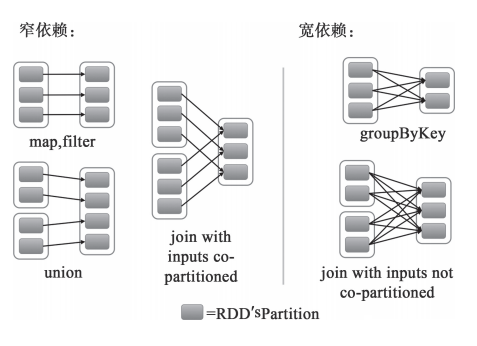
对于groupByKey,子RDD的所有Partition(s)会依赖于parent RDD的所有Partition(s),子RDD的Partition是parent RDD的所有Partition Shuffle的结果,因此这两个RDD是不能通过一个计算任务来完成的。同样,对于需要parent RDD的所有Partition进行join的转换,也是需要Shuffle,这类join的依赖就是宽依赖而不是前面提到的窄依赖了。
*******************************************************
所有的依赖都要实现trait Dependency[T]:
abstract class Dependency[T] extends Serializable {
def rdd: RDD[T]
}
其中rdd就是依赖的parent RDD。
对于窄依赖的实现是:
abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] {
//返回子RDD的partitionId依赖的所有的parent RDD的Partition(s)
def getParents(partitionId: Int): Seq[Int]
override def rdd: RDD[T] = _rdd
}
现在有两种窄依赖的具体实现,一种是一对一的依赖,即OneToOneDependency:
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int) = List(partitionId)
*******************************************************
*******************************************************
通过getParents的实现不难看出,RDD仅仅依赖于parent RDD相同ID的Partition。
还有一个是范围的依赖,即RangeDependency,它仅仅被org.apache.spark.rdd.UnionRDD使用。UnionRDD是把多个RDD合成一个RDD,这些RDD是被拼接而成,即每个parent RDD的Partition的相对顺序不会变,只不过每个parent RDD在UnionRDD中的Partition的起始位置不同。因此它的getPartents如下:
override def getParents(partitionId: Int) = {
if(partitionId >= outStart && partitionId < outStart + length) {
List(partitionId - outStart + inStart)
} else {
Nil
}
}
*******************************************************
*******************************************************
其中,inStart是parent RDD中Partition的起始位置,outStart是在UnionRDD中的起始位置,length就是parent RDD中Partition的数量。
宽依赖的实现只有一种:ShuffleDependency。子RDD依赖于parent RDD的所有Partition,因此需要Shuffle过程:
class ShuffleDependency[K, V, C](
@transient _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Option[Serializer] = None,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]] {
override def rdd = _rdd.asInstanceOf[RDD[Product2[K, V]]]
//获取新的shuffleId
val shuffleId: Int = _rdd.context.newShuffleId()
//向ShuffleManager注册Shuffle的信息
val shuffleHandle: ShuffleHandle =
_rdd.context.env.shuffleManager.registerShuffle(
shuffleId, _rdd.partitions.size, this)
_rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
}
宽依赖支持两种Shuffle Manager,即org.apache.spark.shuffle.hash.HashShuffleManager(基于Hash的Shuffle机制)和org.apache.spark.shuffle.sort.SortShuffleManager(基于排序的Shuffle机制)。
*******************************************************
DAG的生成
原始的RDD(s)通过一系列转换就形成了DAG。RDD之间的依赖关系,包含了RDD由哪些Parent RDD(s)转换而来和它依赖parent RDD(s)的哪些Partitions,是DAG的重要属性。借助这些依赖关系,DAG可以认为这些RDD之间形成了Lineage(血统)。借助Lineage,能保证一个RDD被计算前,它所依赖的parent RDD都已经完成了计算;同时也实现了RDD的容错性,即如果一个RDD的部分或者全部的计算结果丢失了,那么就需要重新计算这部分丢失的数据。
那么Spark是如何根据DAG来生成计算任务呢?首先,根据依赖关系的不同将DAG划分为不同的阶段(Stage)。对于窄依赖,由于Partition依赖关系的确定性,Partition的转换处理就可以在同一个线程里完成,窄依赖被Spark划分到同一个执行阶段;对于宽依赖,由于Shuffle的存在,只能在parent RDD(s) Shuffle处理完成后,才能开始接下来的计算,因此宽依赖就是Spark划分Stage的依据,即Spark根据宽依赖将DAG划分为不同的Stage。在一个Stage内部,每个Partition都会被分配一个计算任务(Task),这些Task是可以并行执行的。Stage之间根据依赖关系变成了一个大粒度的DAG,这个DAG的执行顺序也是从前向后的。也就是说,Stage只有在它没有parent Stage或者parent Stage都已经执行完成后,才可以执行。