Spark HA需要先安装zookeeper,推荐稳定版zookeeper-3.4.6,具体安装如下:
1) 下载Zookeeper
进入http://www.apache.org/dyn/closer.cgi/zookeeper/,你可以选择其他镜像网址去下载,用官网推荐的镜像:http://mirror.bit.edu.cn/apache/zookeeper/


下载zookeeper-3.4.6.tar.gz。

2) 安装Zookeeper
提示:下面的步骤发生在master服务器。
以ubuntu14.04举例,把下载好的文件放到/usr/local/spark目录,用下面的命令解压:
cd /usr/local/spark
tar -zxvf zookeeper-3.4.6.tar.gz
解压后在/usr/local/spark目录会多出一个zookeeper-3.4.6的新目录,解压后配置zookeeper环境变量。
3) 配置Zookeeper
提示:下面的步骤发生在master服务器。
a. 配置.bashrc,添加ZOOKEEPER_HOME环境变量
export ZOOKEEPER_HOME=/usr/local/spark/zookeeper-3.4.6
b. 将zookeeper的bin目录添加到path中
export PATH=${JAVA_HOME}/bin:${ZOOKEEPER_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${SPARK_HOME}/sbin:${HIVE_HOME}/bin:
${KAFKA_HOME}/bin:$PATH
c. 使配置的环境变量立即生效:source ~/.bashrc
d. 创建data和logs目录,data目录用来存放元数据信息,logs用来存放运行日志
- cd $ZOOKEEPER_HOME
- mkdir data
- mkdir logs
e. 创建并打开zoo.cfg文件
- cd $ZOOKEEPER_HOME/conf
- cp zoo_sample.cfg zoo.cfg
- vim zoo.cfg
d. 配置zoo.cfg
# 配置Zookeeper的日志和服务器身份证号等数据存放的目录。
# 千万不要用默认的/tmp/zookeeper目录,因为/tmp目录的数据容易被意外删除。
dataDir=/usr/local/spark/zookeeper-3.4.6/data
dataLogDir=/usr/local/spark/zookeeper-3.4.6/logs
# Zookeeper与客户端连接的端口
clientPort=2181
# 在文件最后新增3行配置每个服务器的2个重要端口:Leader端口和选举端口
# server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;
# B 是这个服务器的hostname或ip地址;
# C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;
# D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,
# 选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
# 如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信
# 端口号不能一样,所以要给它们分配不同的端口号。
server.0=Master:2888:3888
server.1=Work1:2888:3888
server.2=Work2:2888:3888
e. 创建并打开myid文件
- cd $ZOOKEEPER_HOME/data
- touch myid
- vim myid
f. 配置myid
按照zoo.cfg的配置,myid的内容就是0。
4) 同步Master的安装和配置到Work1和Work2
- 在master服务器上运行下面的命令
cd /root
scp ./.bashrc [email protected]:/root
scp ./.bashrc [email protected]:/root
cd /usr/local/spark
scp -r ./zookeeper-3.4.6 [email protected]:/usr/local/spark
scp -r ./zookeeper-3.4.6 [email protected]:/usr/local/spark
--修改Work1中data/myid中的值
vim myid
按照zoo.cfg的配置,myid的内容就是1。
--修改Work2中data/myid中的值
vim myid
按照zoo.cfg的配置,myid的内容就是2。
5) 启动Zookeeper服务
- 在Master服务器上运行下面的命令
zkServer.sh start
- 在Work1服务器上运行下面的命令
source /root/.bashrc //使配置的zookeeper环境变量生效
zkServer.sh start
- 在Work2服务器上运行下面的命令
source /root/.bashrc //使配置的zookeeper环境变量生效
zkServer.sh start
6) 验证Zookeeper是否安装和启动成功
- 在master服务器上运行命令:jps和zkServer.sh status
[email protected]:/usr/local/spark/zookeeper-3.4.6/bin# jps
3844 QuorumPeerMain
4790 Jps
zkServer.sh status //需在安装的各个节点启动zookeeper
[email protected]:/usr/local/spark/zookeeper-3.4.6/bin# zkServer.sh status
JMX enabled by default
Using config: /usr/local/spark/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
- 在Work1服务器上运行命令:jps和zkServer.sh status
source /root/.bashrc
[email protected]:/usr/local/spark/zookeeper-3.4.6/bin# jps
3462 QuorumPeerMain
4313 Jps
[email protected]:/usr/local/spark/zookeeper-3.4.6/bin# zkServer.sh status
JMX enabled by default
Using config: /usr/local/spark/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
- 在Work2服务器上运行命令:jps和zkServer.sh status
[email protected]Work2:/usr/local/spark/zookeeper-3.4.6/bin# jps
4073 Jps
3277 QuorumPeerMain
[email protected]Work2:/usr/local/spark/zookeeper-3.4.6/bin# zkServer.sh status
JMX enabled by default
Using config: /usr/local/spark/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: leader
至此,代表Zookeeper已经安装和配置成功。
Zookeeper安装和配置完成后,需配置Spark的HA机制,进入到spark安装目录的conf目录下,修改spark-env.sh文件
vim spark-env.sh
添加zookeeper支持,进行状态恢复:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=Master:2181,Work1:2181,Work2:2181 -Dspark.deploy.zookeeper.dir=/spark"
注释掉:因为用zookeeper进行HA机制,不需要指定Master
#export SPARK_MASTER_IP=Master
将配置好的文件同步到Work1及Work2上面
scp spark-env.sh [email protected]:/usr/local/spark/spark-1.6.1-bin-hadoop2.6/conf
scp spark-env.sh [email protected]:/usr/local/spark/spark-1.6.1-bin-hadoop2.6/conf
通过完成后,启动spark集群
./start-all.sh
启动后如下所示:

![]() 这里问个问题,我们上面在spark-env.sh中注释掉了SPARK_MASTER_IP=Master,那为什么我们启动spark,会启动Master,为什么?
这里问个问题,我们上面在spark-env.sh中注释掉了SPARK_MASTER_IP=Master,那为什么我们启动spark,会启动Master,为什么?
原因是我们在slaves文件中配置了Work1和Work2节点,故这里默认启动了Master,但是这里我们只有一个Master,我们上面通过zookeeper配置了3台master进行HA,
所以我们需要手动到Work1和Work2上启动Master
./start-master.sh
通过jps查看Master是否启动成功,这时候我们spark集群有3个master。
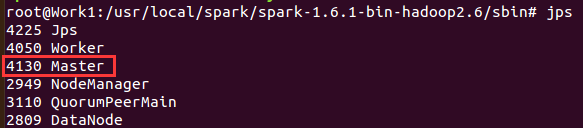
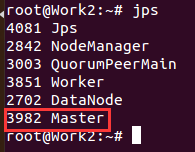
通过Work1:8080和Work2:8080地址查看Master状态为 STANDBY,在等待服务中,暂时什么也没有,只有Master上有。
现在来测试下Spark HA,启动Spark shell,注意:我们现在没有明确指定哪台机器为Master,所以我们不能只写一台,具体命令如下:
./spark-shell --master spark://Master:7077,Work1:7077,Work2:7077
这时候程序运行在集群上,需要向zookeeper去找一台Master=ALIVE的机器,会和3台机器进行连接,最后只会和ALIVE机器进行交互
这时候如果我们手动停止Master,这时候会失去了对Master的连接,这时候会等待被选中的Master去连接他,这时候zookeeper就会在Work1和Work2上去恢复,谁恢复完谁就是Leader,这中间需要时间
适集群情况而定。

这时候可以看到Master从Master机器切换到Work1机器上,也可以通过WebUI去查看,这时候发现Master:7077无法启动,Work1:7077变成了ALIVE,如果在Master机器上重新启动Master,可以发现
Work1:7077还是处于ALIVE状态,Master节点不会进行切换。


Spark HA机制就分享到这。
备注:
资料来源于:DT_大数据梦工厂(IMF传奇行动绝密课程)-IMF
更多私密内容,请关注微信公众号:DT_Spark
如果您对大数据Spark感兴趣,可以免费听由王家林老师每天晚上20:00开设的Spark永久免费公开课,地址YY房间号:68917580
Life is short,you need to Spark.