最近一周几乎都在做关于yarn的资源隔离的事情,也重新看了一下以前看过的关于yarn的书,这次就当是写写自己的工作总结吧。
之所以要做资源隔离,是因为现在公司内部有很多团队都在使用yarn来提交各式各样的任务,例如hive的mapreduce,spark在yarn上的部署,sqoop导数据等等,为了防止单个任务使用过多资源,而导致整个集群的其他任务不可运行,所以就要使用yarn的资源隔离了。
虽然yarn中,有Capacity Scheduler以及Fair Scheduler这两种方式来实现资源在不同任务(准确的说应该是队列)之间的调度,但是个人感觉这两种分配策略在资源隔离上面真的没有什么太大的区别,因为两者都可以对各个队列限制使用的最大最小资源;而且也可将现有资源划分为不同的队列,每个应用只在特定的队列提交。当然对于队列内部任务之间的资源隔离,Fair Scheduler支持的方式多了一种FIFO策略,由于公司使用的hadoop默认使用Fair Scheduler,所以最后还是使用的Fair策略。下面大概讲一下自己是怎么做的吧。
step1:针对不同的开发团队,建立不同的用户,就比如下面的截图,针对两个group分别建立了group1以及group2这两个用户:
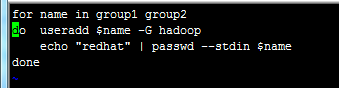
step2:修改权限
这里的权限包括hadoop权限、hdfs权限,这就要根据自己的实际情况来看了;
step3:修改yarn-site.xml
主要修改了以下几个参数
yarn.resourcemanager.scheduler.class:配置使用哪种Scheduler,由于使用的是FairScheduler,所以设置为org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
yarn.scheduler.fair.allocation.file:指定分配策略文件路径
yarn.scheduler.fair.preemption:是否支持队列之间的资源抢占,虽然设置为false,但是还是多多少少会出现繁忙队列抢占了一点空闲队列资源的现象
关于yarn-site的配置参数还有很多,大家可以在网上找找;
step4:编写fair scheduler的具体配置文件,在自己测试的时候,大概如下面的截图

首先简单介绍一下,yarn中资源是按照队列(或者说是资源池)来分配的,队列有自己的子队列,而root队列就像java中的Object队列一样(如果没有设置,所有应用向root.default队列提交应用),是所有队列的父队列。在上面的配置文件中,这对group1队列定义了如下规则:
1.group1以及group2这两个root队列的子队列(这里队列命名跟用户命名一样);
2.group1队列最少保留10G内存、10个cpu内核,最多使用15G内存、15个cpu内核;
3.队列内的应用才用公平的调度策略分配资源,最多可以在group1内运行50个应用;
4.只有group1以及hadoop用户可以向group1队列提交应用;
5.只用hadoop用户可以管理group1队列(即只有hadoop可以kill这上面的应用)。
step5:重启yarn
最后通过spark-shell --master yarn --num-executors --executor-memory --queue测试,发现的确可以做到资源隔离,达到如下效果:
1.group1用户只能向group1队列提交应用,而且即使使用资源大于最大值,也只是会略微超过一点点,不会超过很多(有兴趣的朋友可以自己试试);
2.group1用户是不能向group2队列提交任务的;
3.hadoop用户还是可以向group1、group2、default三个队列提交任务,这样可以保证系统有个类似root用户的角色。
但是发现没能实现acl的功能,即无论是hadoop、group1、group2还是任何可以执行yarn命令的用户都可以通过yarn application -kill杀死任何队列上的程序。多次参考书本以及官网,但是仍然没有成功,最后不得已,只能说是控制yarn命令的权限为700,只让hadoop用户可以执行这个命令,希望以后可以找出更好地解决方案。
2017年1月7日