RDD的操作
RDD支持两种操作:转换和动作。
1)转换,即从现有的数据集创建一个新的数据集。
2)动作,即在数据集上进行计算后,返回一个值给Driver程序。
例如,map就是一种转换,它将数据集每一个元素都传递给函数,并返回一个新的分布式数据集表示结果。另一个方面,reduce是一种动作,通过一些函数将所有元素叠加起来,并将最终结果返回Driver(还有一个并行的reduceByKey,能返回一个分布式数据集)。
下图描述了从外部数据源创建RDD,经过多次转换,通过一个动作操作将结果写回外部存储系统的逻辑运行图。整个过程的计算都是在Worker中的Executor中运行。

图 1 RDD的创建、转换和动作的逻辑计算图
RDD的转换
RDD中的所有转换都是惰性的,也就是说,它们并不会直接计算结果。相反的,它们只是记住这些应用到基础数据集(例如一个文件)上的转换动作。只有当发生一个要求返回结果给Driver的动作时,这些转换才会真正运行。这个设计让Spark更加有效率地运行。例如我们可以实现:通过map创建的一个新数据集,并在reduce中使用,最终只返回reduce的结果给Driver,而不是整个大的新数据集。图2描述了RDD在进行groupByRey时的内部RDD转换的实现逻辑图。图3描述了reduceByKey的实现逻辑图。

图2 RDD groupByKey的逻辑转换图
在groupByKey的操作中,会在MapPartitionsRDD做一次Shuffle,图2中设置的分片数量是3,因此ShuffledRDD会有3个分片,ShuffledRDD实际上仅仅是从上游的任务中读取Shuffle的结果,因此图的箭头是指向上游的MapPartitionsRDD的。关于Shuffle的实现实际上要比图中展示得复杂得多。reduceByKey和groupByKey的实现差不多,它在Shuffle完成之后,需要做一次reduce。
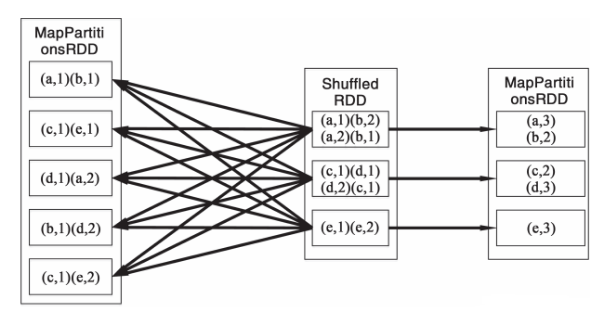
图3 RDD reduceByKey 的逻辑转换图
默认情况下,每一个转换过的RDD都会在它执行一个动作时被重新计算。不过也可以使用persist(或者cache)方法,在内存中持久化一个RDD。在这种情况下,Spark将会在集群中保存相关元素,下次查询这个RDD时能更快访问它。也支持在磁盘上持久化数据集,或在集群间复制数据集。