下面都是以网络读数据为例
【2阶段网络IO】
第一阶段:等待数据 wait for data
第二阶段:从内核复制数据到用户 copy data from kernel to user
下面是5种网络IO模型

【阻塞blocking IO】
两阶段全程阻塞
recvfrom -> [syscall -> wait -> copy ->] return OK

【非阻塞nonblocking IO】
第一阶段是非阻塞的不断检查是否数据准备好,第二阶段阻塞读取数据
recvfrom -> [syscall -> wait ->] return no data ready
recvfrom -> [syscall -> wait ->] return no data ready
recvfrom -> [syscall -> wait ->] return ready
recvfrom -> [syscall -> copy ->] return OK

【多路复用IO multiplexing】
每个IO都是非阻塞IO,第一阶段通过select/poll方法,一次性轮询多个IO句柄,检查是否有IO句柄准备好,第二阶段阻塞读取数据
select/pool -> [syscall -> wait ->] return readable
recvfrom -> [syscall -> copy ->] return OK

【信号驱动signal driven IO】
第一阶段构造一个信号处理器,第二阶段阻塞读取数据
signal handle -> [syscall -> wait ->] return
[syscall ->] signal handle -> recvfrom -> [syscall -> copy ->] return OK

【异步asynchronous IO】
两阶段都是非阻塞
aio_read -> [syscall -> wait ->] return
[syscall -> copy ->] aio_read callback

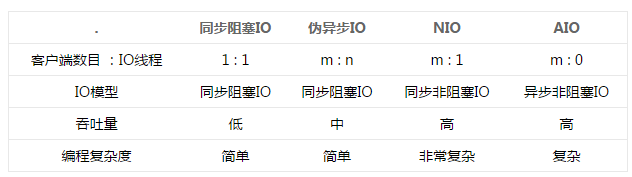
5种网络IO对比,只有aio才是全程非阻塞,其它4种都是同步IO。
阻塞IO编程简单,这种方式使用很广泛,但是效率较低。
非阻塞IO效率较高,但是编程较复杂,有开发语言和代码库支持就简单多了。
多路复用非阻塞IO效率比非阻塞IO更高,在大规模的网络IO处理中尤其明显,支持的程序也越来越多。
异步IO效率很高,但是编程很复杂。node.js中使用的就是异步IO。
【select / epoll 对比】
select不足的地方:
1 每次select都要把全部IO句柄复制到内核
2 内核每次都要遍历全部IO句柄,以判断是否数据准备好
3 select模式最大IO句柄数是1024,太多了性能下降明显
epoll的特点
1 每次新建IO句柄(epoll_create)才复制并注册(epoll_ctl)到内核
2 内核根据IO事件,把准备好的IO句柄放到就绪队列
3 应用只要轮询(epoll_wait)就绪队列,然后去读取数据
只需要轮询就绪队列(数量少),不存在select的轮询,也没有内核的轮询,不需要多次复制所有的IO句柄。因此,可以同时支持的IO句柄数轻松过百万。
网络编程,一定要非常了解网络IO模型,对系统设计和架构选型才能有更好的选择和把握。
在实战课程 《PHP秒杀系统 高并发高性能的极致挑战》中,也是针对这类高并发的业务场景做了特定的性能优化以及分布式方案,大家可以参考学习。
作者:一凡Sir
链接:https://www.imooc.com/article/37093
来源:慕课网
本文原创发布于慕课网 ,转载请注明出处,谢谢合作
原文地址:https://www.cnblogs.com/makai/p/11087553.html