模型评估与参数调优实战
基于流水线的工作流
一个方便使用的工具:scikit-learn中的Pipline类。它使得我们可以拟合出包含任意多个处理步骤的模型,并将模型用于新数据的预测。
加载威斯康星乳腺癌数据集
1.使用pandas从UCI网站直接读取数据集
import pandas as pd df=pd.read_csv(‘https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data‘,header=None)
2.接下来,将数据集的30个特征的赋值给一个Numpy的数组对象X.使用scikit-learn中的LabelEncoder类,我们可以将类标从原始的字符串表示(M或者B)转换为整数:
from sklearn.preprocessing import LabelEncoder X=df.loc[:,2:].values y=df.loc[:,1].values le=LabelEncoder() y=le.fit_transform(y)
转换后的类标(诊断结果)存储在一个数组y中,此时恶性肿瘤和良性肿瘤分别被标识为类1和类0,我们可以通过调用LabelEncoder的transform方法来显示虚拟类标(0和1)
3.在构建第一个流水线模型钳,先将数据集划分为训练数据集(原始数据集80%的数据)和一个单独的测试数据集(原数据集的20%的数据)
from sklearn.cross_validation import train_test_split X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=1)
在流水线中集成数据转换及评估操作
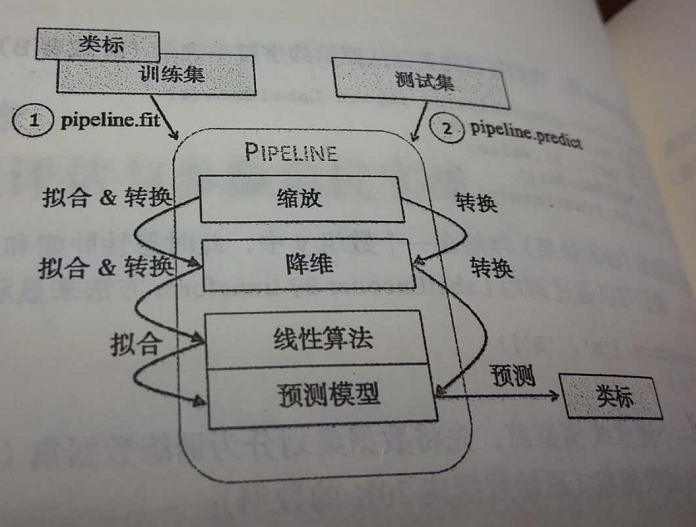
我们想通过PCA,将最初的30维数据压缩到一个二维的子空间上。我们无需在训练数据集和测试集上分别及逆行模型拟合、数据转换,而是通过流水线将StandardScaler、PCA,以及LogisticRegression对象串联起来:
from sklearn.preprocessing import StandardScaler from sklearn.decomposition import PCA from sklearn.linear_model import LogisticRegression from sklearn.pipeline import Pipeline pipe_lr=Pipeline([(‘scl‘,StandardScaler()),(‘pca‘,PCA(n_components=2)),(‘clf‘,LogisticRegression(random_state=1))]) pipe_lr.fit(X_train,y_train) print(‘Test Accuracy:%.3f‘%pipe_lr.score(X_test,y_test))
Pipline对象采用元祖的序列作为输入,其中每个元祖中的第一个值为一个字符串,它可以是任意标识符,我们通过它来访问流水线中的元素,而元祖的第二个值则为scikit-learn中的一个转换器或者评估器
流水线中包含了scikit-learn中用于数据预处理的类,最后还包括了一个评估器。在前面的示例代码中,流水线中有两个预处理环节,分别是用于数据缩放和转换的的StandardScaler及PCA,最后还有一个作为评估器的逻辑斯蒂回归分类器。在流水线pipe_lr上执行fit方法时,StandardScaler会在训练数据上执行fit和transform操作,经过转换后的训练数据将传递给流水线上的下一个对象——PCA。与前面的步骤类似,PCA会在前一步转换后的输入数据上执行fit和transform操作,并将处理过的数据传递给流水线中的最后一个对象——评估器。我们应该注意到:流水线中没有限定中间步骤的数量。流水线的工作方式可用下图来描述:
使用K折交叉验证评估模型性能
构建机器学习模型的一个关键步骤就是在新数据上对模型的性能进行评估。
常用的交叉验证技术:holdout交叉验证和k折交叉验证。
holdout交叉验证
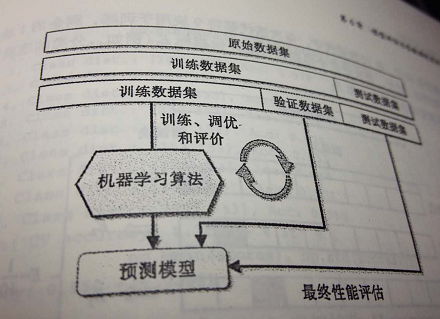
holdout交叉验证是评估机器学习模型泛化性能的一个经典且常用的方法。通过holdout方法,我们将最初的数据集划分为训练数据集和测试数据集:前者用于模型的训练,后者用于性能的评估。然而,在典型的机器学习应用中,为进一步提高模型在预测未知数据上的性能,我们还要对不同参数设置进行调优和比较。该过程称为模型选择,指的是针对给定分类问题我们调整参数以寻求最优值(也称为超参)的过程。
使用holdout进行模型选择更好的方法是将数据划分为三个部分:训练数据集、验证数据集和测试数据集。训练数据集用于不同模型的拟合,模型在验证数据集上的性能表现作为模型选择的标准。使用模型训练及模型选择阶段不曾使用的数据作为测试数据集的优势在于:评估模型应用于新数据上能够获得较小偏差。下图是holdout交叉验证的一些概念。
holdout方法的一个缺点在于:模型性能的评估对训练数据集划分为训练及验证子集的方法是敏感的;评估的结果会随样本的不同而发生变化。
k折交叉验证
在k折交叉验证中,我们不重复地随机将训练数据集划分为k个,其中k-1个用于模型训练,剩余的1个用于测试。重复此过程k次,我们就得到了k个模型及对模型性能的评价。
基于这些独立且不同的数据子集上得到的模型性能评价结果,我们可以计算出其平均性能。与holdout方法相比,这样得到的结果对数据划分方法的敏感性相对较低。通常情况下,我们将k折交叉验证用于模型的调优,也就是找到使得模型泛化性能最优的超参值。一旦找到了满意的超参值,我们就可以在全部的训练数据上重新训练模型,并使用独立的测试数据对模型性能做出最终评估。
由于k折交叉验证使用了无重复抽样技术,该方法的优势在于(每次迭代过程中)每个样本点只有一次被划入训练数据集或测试数据集的机会,与holdout方法相比,这将使得模型性能的评估具有较小的方差
import numpy as np
from sklearn.cross_validation import StratifiedKFold
kfold=StratifiedKFold(y=y_train,n_folds=10,random_state=1)
scores=[]
for k,(train,test) in enumerate(kfold):
pipe_lr.fit(X_train[train],y_train[train])
score=pipe_lr.score(X_train[test],y_train[test])
scores.append(score)
print(‘Fold:%s,Class dist.:%s,Acc:%.3f‘%(k+1,np.bincount(y_train[train]),score))
首先,我们用训练集中的类标y_train来初始化sklearn.cross_validation模块下的StratifiedKfold迭代器,并通过n_folds参数来设置块的数量。当我们使用kfold迭代器在k个块中进行循环时,使用train中返回的索引去拟合前面所构建的逻辑斯蒂回归流水线。通过pile_lr流水线,我们可以保证每次迭代中样本都得到适当的缩放(如标准化)。然后使用test索引计算模型的准确率,并将其存储在score列表中,用于计算平均准确率以及性能评估标准差。
通过学习及验证曲线来调试算法
两个有助于提高学习算法性能的简单但功能强大的判定工具:学习曲线与验证曲线。
使用学习曲线判定偏差和方差问题
如果一个模型在给定训练数据上构造得过于复杂——模型中有太多的自由度或者参数——这时模型可能对训练数据过拟合,而对未知数据泛化能力低下。通常情况下,收集更多的训练样本有助于降低模型的过拟合程度。但在实践中,收集更多的数据会带来高昂的成本,或者根本不可行。通过将模型的训练及准确性验证看作是训练数据集大小的函数,并绘制其图像,我们可以很容易看出模型是面临高方差还是高偏差的问题,以及收集更多的数据是否有助于解决问题。讨论模型常见的两个问题:
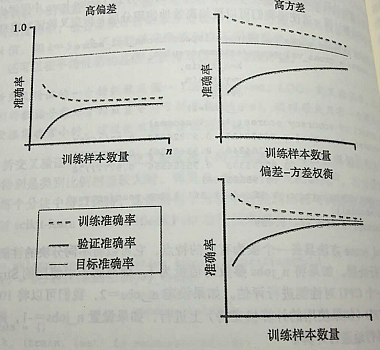
左上图像显示的是一个高偏差模型。此模型的训练准确率和交叉验证准确率都很低,这表明此模型未能很好地拟合数据。解决此问题的常用方法是增加模型中参数的数量。右上方图像中的模型面临高方差的问题,表明训练准确度与交叉验证准确度之间有很大差别。针对此类过拟合问题,我们可以收集更多的训练数据或者降低模型的复杂度,如增加正则化的参数。
如何使用scikit-learn中的学习曲线函数评估模型:
import matplotlib.pyplot as plt from sklearn.learning_curve import learning_curve pipe_lr=Pipeline([(‘scl‘,StandardScaler()),(‘clf‘,LogisticRegression(penalty=‘l2‘,random_state=0))]) train_size,train_scores,test_scores=learning_curve(estimator=pipe_lr,X=X_train,y=y_train,train_sizes=np.linspace(0.1,1,10),cv=10,n_jobs=1) train_mean=np.mean(train_scores,axis=1) train_std=np.std(train_scores,axis=1) test_mean=np.mean(test_scores,axis=1) test_std=np.std(test_scores,axis=1) plt.plot(train_size,train_mean,color=‘blue‘,marker=‘o‘,markersize=5,label=‘training accuracy‘) plt.fill_between(train_size,train_mean+train_std,train_mean-train_std,alpha=0.15,color=‘blue‘) plt.plot(train_size,test_mean,color=‘green‘,linestyle=‘--‘,marker=‘s‘,markersize=5,label=‘validation accuracy‘) plt.fill_between(train_size,test_mean+test_std,test_mean-test_std,alpha=0.15,color=‘green‘) plt.grid() plt.xlabel(‘Number of training samples‘) plt.ylabel(‘Accuracy‘) plt.legend(loc=‘lower right‘) plt.ylim([0.8,1.0]) plt.show()
通过learning_curve函数的train_size参数,我们可以控制用于生成学习曲线的样本的绝对或相对数量。在此,通过设置train_sizes=np.linspace(0.1,1,10)来使用训练数据集上等距间隔的10个样本。默认情况下,learning_curve函数使用分层k折交叉验证来计算交叉验证的准确性,通过cv参数将k的值设置为10.然后,我们可以简单地通过不同规模训练集上返回地交叉验证和测试评分来计算平均地准确率,并且我们使用matplotlib的plot函数绘制出准确率图像。此外,在绘制图像时,我们通过fill_between函数加入了平均准确率标准差的信息,用于表示评价结果的方差。
通过验证曲线来判定过拟合与欠拟合
验证曲线是一种通过定位过拟合或欠拟合等诸多问题所在,来帮助提高模型性能的有效工具。验证曲线与学习曲线相似,不过绘制的不是样本大小与训练准确率、测试准确率之间的关系函数,而是准确率与模型参数之间的关系。
from sklearn.learning_curve import validation_curve param_range=[0.001,0.01,0.1,1,10,100] train_scores,test_scores=validation_curve(estimator=pipe_lr,X=X_train,y=y_train,param_name=‘clf__C‘,param_range=param_range,cv=10) train_mean=np.mean(train_scores,axis=1) train_std=np.std(train_scores,axis=1) test_mean=np.mean(test_scores,axis=1) test_std=np.std(test_scores,axis=1) plt.plot(param_range,train_mean,color=‘blue‘,marker=‘o‘,markersize=5,label=‘training accuracy‘) plt.fill_between(param_range,train_mean+train_std,train_mean-train_std,alpha=0.15,color=‘blue‘) plt.plot(param_range,test_mean,color=‘green‘,linestyle=‘--‘,marker=‘s‘,markersize=5,label=‘validation accuracy‘) plt.fill_between(param_range,test_mean+test_std,test_mean-test_std,alpha=0.15,color=‘green‘) plt.grid() plt.xscale(‘log‘) plt.legend(loc=‘lower right‘) plt.xlabel(‘Parameter C‘) plt.ylabel(‘Accuracy‘) plt.ylim([0.8,1]) plt.show()
与learning_curve函数类似,如果我们使用的是分类算法,则validation_curve函数默认使用分层k折交叉验证来评估模型的性能。在validation_curve函数内,我们可以指定想要验证的参数。
使用网格搜索调优机器学习模型
在机器学习中,有两类参数:一类通过训练数据学习得到的参数。另一类即为调优参数,也称超参。一种功能强大的超参数优化技巧:网格搜索,它通过寻找最优的超参值得组合以进一步提高模型得性能。
使用网格搜索调优超参
网格搜索法非常简单,它通过对我们指定得不同超参列表进行暴力穷举搜索,并计算估计每个组合对模型性能的影响,以获得参数的最优组合
from sklearn.grid_search import GridSearchCV
from sklearn.svm import SVC
pipe_svc=Pipeline([(‘scl‘,StandardScaler()),(‘clf‘,SVC(random_state=1))])
param_range=[0.0001,0.001,0.01,0.1,1,10,100,1000]
param_grid=[{‘clf__C‘:param_range,‘clf__kernel‘:[‘linear‘]},{‘clf__C‘:param_range,‘clf__gamma‘:param_range,‘clf__kernel‘:[‘rbf‘]}]
gs=GridSearchCV(estimator=pipe_svc,param_grid=param_grid,scoring=‘accuracy‘,cv=10,n_jobs=-1)
gs=gs.fit(X_train,y_train)
print(gs.best_score_)
print(gs.best_params_)
使用上述代码,我们初始化了一个sklearn.grid_search模块下的GridSearchCV对象,用于对支持向量机流水线的训练与调优。我们将GridSearchCV的param_grid参数以字典的方式定义为待调优的参数。对于线性SVM来说,我们只需调优正则化参数(C);对基于RBF的核SVM,我们同时需要调优C和gamma参数。请注意此处的gamma是针对核SVM特别定义的。在训练数据集上完成网格搜索后,可以通过best_score_属性得到最优模型的性能评分,具体参数信息可以通过best_params_属性得到。
通过嵌套交叉验证选择算法
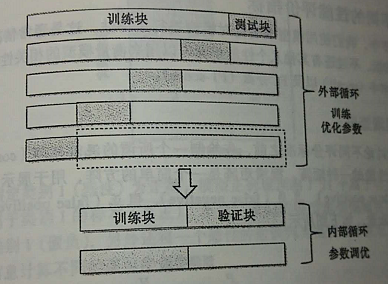
结合网格搜索进行k折交叉验证,通过超参数值得改动对机器学习模型进行调优,这是一种有效提高机器学习模型性能的方法。如果要在不同机器学习算法中做出选择,则推荐另一种方法——嵌套交叉验证,在一项对误差估计的偏差情形研究中,使用嵌套交叉验证,估计得真是误差与在测试集上得到的结果几乎没有差距。
在嵌套交叉验证的外围循环中,我们将数据划分为训练块及测试块;而在用于模型选择的内部循环中,我们则基于这些训练块使用k折交叉验证。在完成模型的选择后,测试块用于模型性能的评估。下图通过5个外围块 及2个内部模块解释了嵌套交叉验证的概念,也称为5×2交叉验证。
原文地址:https://www.cnblogs.com/yifdu25/p/8445914.html