K-Means 算法是一种聚类算法,聚类当然是无监督了,给定初始数据集 $\left \{x_i \right\}_{i=1}^N$ ,K-Means 会把数据分成 $K$ 个簇,每个簇代表不同的类别,K-Means 算法如下:
1. 从训练集 $\left \{x_i \right\}_{i=1}^N$ 中选取 K 个质心, 分别为 $\left \{\mu_k \right\}_{k=1}^K$ ;
2. 重复一下过程直到收敛 :
2.1 对于样本 $x_i$ ,得到其类别 $c_i$ :\[c_i = \arg \min_k||x_i – \mu_k||^2\].
2.2 对于每一个簇 $k$ ,重新计算质心:\[ \mu_k=\frac{\sum_{i=1}^N 1\left \{ c_i = k \right \}x_i}{\sum_{i=1}^N 1\left \{ c_i = k \right \}}\]
聚类完成后,用 $\left \{C_k \right\}_{k=1}^K$ 表示得到 $K$ 个簇,可以定义一个损失来衡量聚类的效果,该损失同时可用作为迭代的停止条件,其形式如下:
\[J = \sum_{k}\sum_{x_i\in C_k}||x_i-\mu_k||^2\]
当两次迭代的损失 $J$ 基本不发生变化,或者每个簇的样本基本不发生变化时,迭代便可停止。下图为 K-Means 的过程:
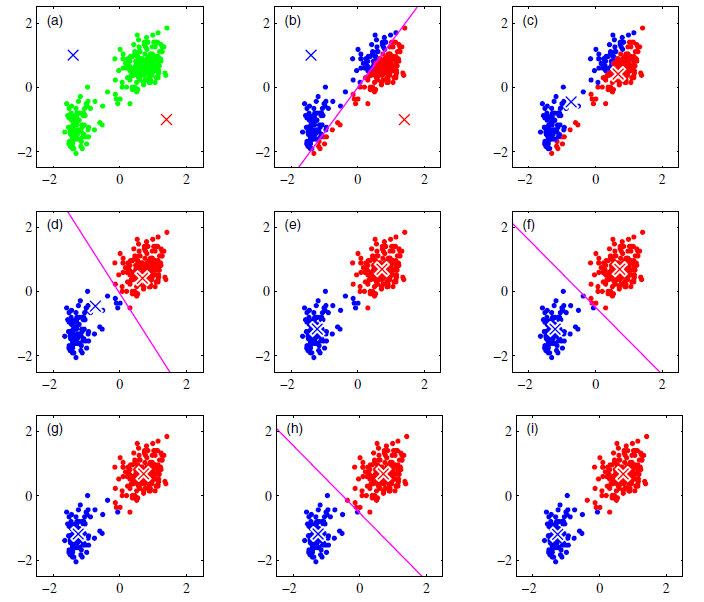
K-Means 非常简单,实际应用中有两个关键问题,分别是:K 值的选取 与 初始质心的选择,下边分别来讨论之:
K值选取:
1)Elbow Method :当选择的k值小于真正的时,k每增加1,cost值就会大幅的减小;当选择的k值大于真正的K时, k每增加1,cost值的变化就不会那么明显。这样,正确的k值就会在这个转折点,类似elbow的地方。 如下图

2)
BIC的计算公式如下:
\[BIC = –2 \ln(likelihood) +ln(N) \times K\]
?其中,N是数据集中的样本数目,k特征数目。BIC是对模型拟合程度和复杂度的一种度量方式,计算公式中的-2*ln(likehood)部分是对模型拟合度的度量,这个值越大,说明拟合程度越差。模型复杂度由ln(N)*k度量。
?似然函数一般是通过概率计算的,即L(θ)=∏p(y|x;θ),是一个介于0到1的小数值,结合ln函数的图像可知ln(likehood)是一个负数,且似然函数越小,对应的就是一个绝对值越大的负数,所以-2*ln(likehood)越大,说明模型拟合度越差。如果模型有似然函数(如GMM),用BIC、DIC等决策;即使没有似然函数,如KMean,也可以搞一个假似然出来,例如用GMM等来代替
初始质心选择:
1)K-Means++ 的方法,首先随机选择一个点作为第一个初始类簇中心点,然后选择距离该点最远的那个点作为第二个初始类簇中心点,然后再选择距离前两个点的最近距离最大的点作为第三个初始类簇的中心点,以此类推,直至选出K个初始类簇中心点。
2)k-menasII算法在每次循环中选取多个points作为准centroid(准centroid是将来有可能会成为centroid的点),循环n次之后,会选取 足够多的准centroids。准centroid的数量要远大于k,而且在每次循环中选取的准centroid数量一般也会非常多, 例如每次选1000个,这样循环的次数要比k小很多,计算效率就会高很多。最后对C中的准centroid再进行聚类(可以使用k-means++算法),将聚类结果中的k个centroid作为原数据的k个 centroid。这样不仅选centroid时的计算效率提高了,而且选出的k个centroid的位置也会比较好,因为是再聚类生成的centroid。k-means II算法相比k-means++算法更适合并行计算,因为它没有要求去严格的选取k个点作为centroids, 只是预选,这样把1-5步放到不同的机器去计算,最后把选取的所有点在reducer中聚到一起, 再聚类,结果和非并行计算也是差不多的。
如果觉的效果还不好,
参考文献
http://kunlun.info/2016/03/25/kmeans_essential/
http://www.cnblogs.com/washa/p/4027284.html K值选择
http://www.cnblogs.com/kemaswill/archive/2013/01/26/2877434.html 初始质心的选择
http://www.xuebuyuan.com/2096905.html
http://blog.jqian.net/post/k-means.html