微软给我们提供了一种非常好用的数据库迁移方案,但是我发现周围的同学用的并不多,所以我还是想把这个方案整理一下。.NET选手看过来,特别是还在通过手工执行脚本来迁移数据库的同学们,当然你也可以选择EF的Migration方案和FluentMigrator,但是下面我介绍的这种方案符合我对团队协作的所有要求,对开发者而言使用起来非常方便,不容易犯错。
一、方案目标
一个好的数据库迁移方案在我看来需要满足以下条件:
1、适用于每个开发者拥有自己独立的数据库开发环境,用于不同feature的并行开发
2、能够配合版本控制工具,不同的版本能够方便合并和易于解决冲突
3、数据库开发环境要易于在不同的版本之间切换
4、易于跟CI工具集成,不同的开发环境(Dev,QA,Staging,Product)能够部署不同的数据库开发环境
5、DBA能够方便审核开发人员提交的数据库脚本
6、整个数据库的迁移过程由脚本自动化完成,不应该有人工干涉
二、准备
假设我们有一个数据库blog,该数据库中包含一个表Users,数据库初始脚本:
Create Database Blog GO USE [Blog] GO /****** Object: Table [dbo].[Users] Script Date: 2016/7/31 17:18:09 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[Users]( [Id] [int] IDENTITY(1,1) NOT NULL, [UserName] [nvarchar](200) NULL, [Email] [nvarchar](100) NULL, [Age] [int] NULL, CONSTRAINT [PK_Users] PRIMARY KEY CLUSTERED ( [Id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO
如图所示,我们得到了一个初始的数据库版本:

三、新建数据库迁移解决方案
1、打开vs, 我用的是vs2015
2、如图所示,新建工程
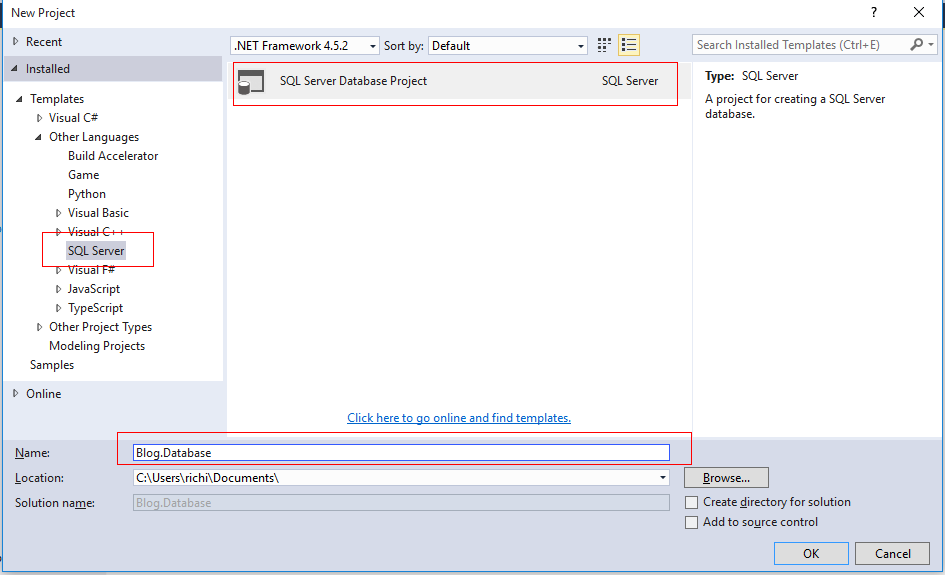
3,在Blog.Database工程,右键,选择Schema Compare…

4、点击中间的“交换位置”图标,左边代表源(Source),右边代表目标(Destination)。我们现在要本地数据库把schema更新在我们新建的数据库工程中。

5、在“源”中选择Select source
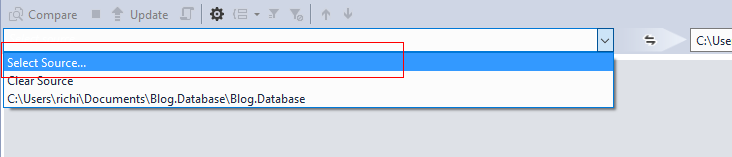
6、按照下图所示添加数据库连接
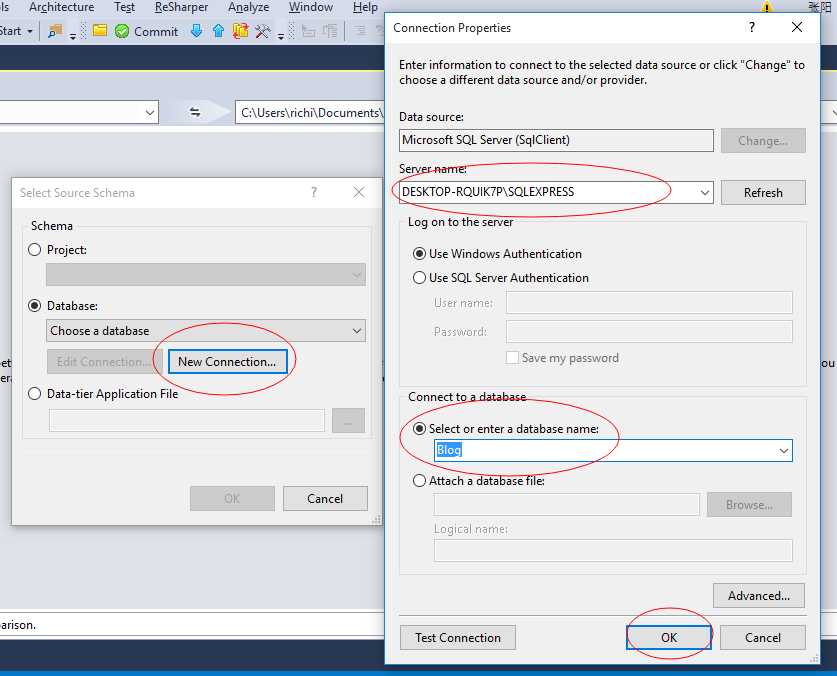
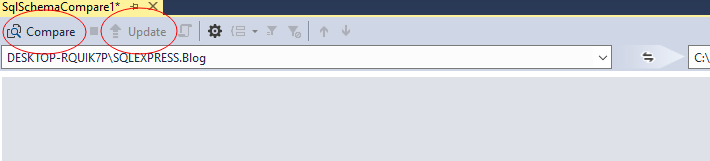
7、Compare 然后Update,数据库中的schema将会同步在我们的vs解决方案中
四、添加存储过程
至此为止我们已经添加了对Blog数据库的迁移方案,所有开发人员对数据库的更改都要通过该解决方案来完成。
比如开发者A这时候需要添加第一个存储过程:
1、在dbo目录下新建Stored Procedures文件夹
2、新建存储过程脚本GetUser.sql
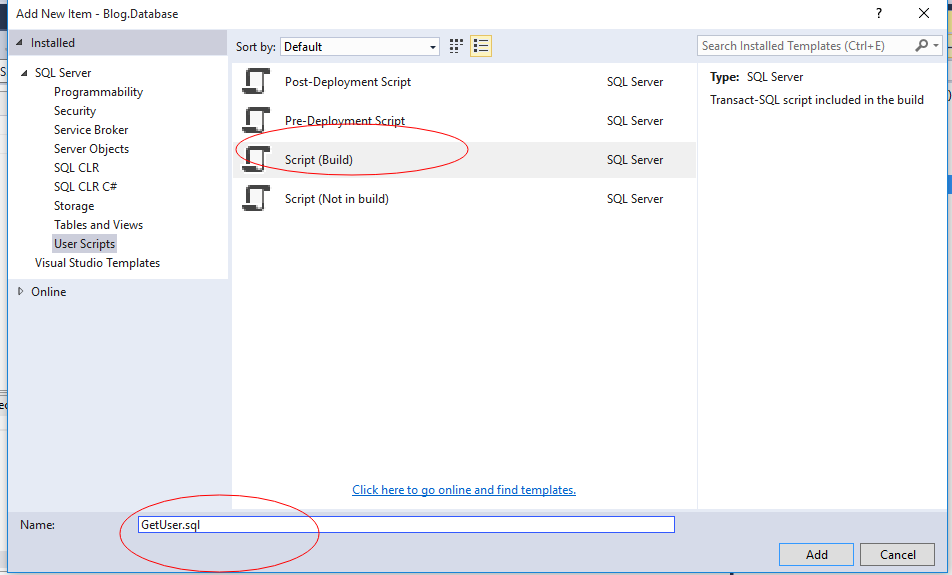
编写以下存储过程:
-- =============================================
-- Author: <Author,,Name>
-- Create date: <Create Date,,>
-- Description: <Description,,>
-- =============================================
CREATE PROCEDURE GetUser
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
-- Insert statements for procedure here
SELECT TOP 100* FROM Users
END
脚本已经编写完毕,这时候开发者A需要把这个更改更新到本地的数据库中:
这时候“源”是我们的数据库迁移方案,目标是本机的数据库,compare然后update

以git为例,开发人员此时会把Blog.Database解决方案更改合并到develop分支,其他开发人员通过compare-update操作将别人对数据库的更改update到本地。
五、更改表结构
开发人员B在另一个分支需要对表User添加两列:Gender和Description,直接在解决方案中打开User表做更改
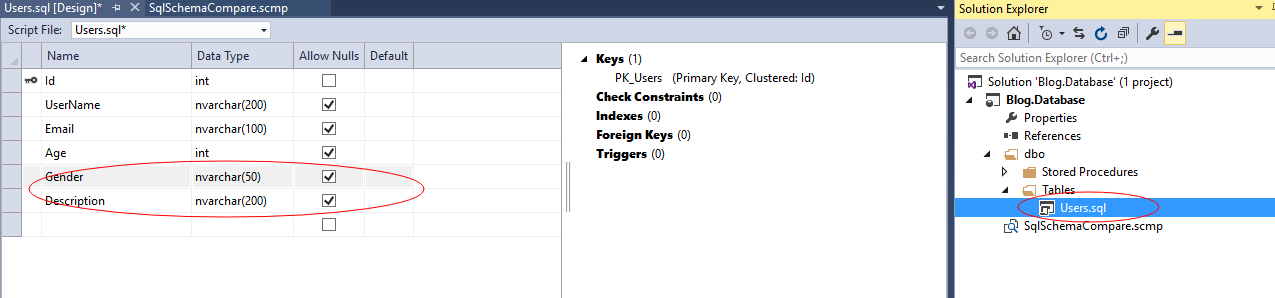
当然最后要通过Compare-Update操作将更改应用到本地数据库,其他开发人员也会通过相同的方式将此更改应用在本地。
六、添加Reference Data
开发人员添加了一个表Gender,并且需要添加三条固定数据:
在Tables文件夹下右键-Tabel-Gender
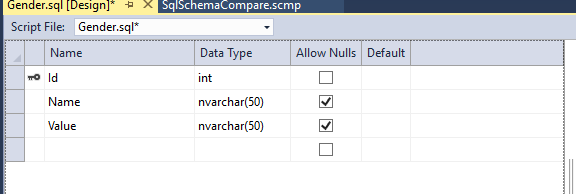
这时候需要添加三条固定数据:Male,Female,Unknown,这时候要用到PostDeploymentSql:
1、新建PostDeploymentSql

2、新建Gender.sql
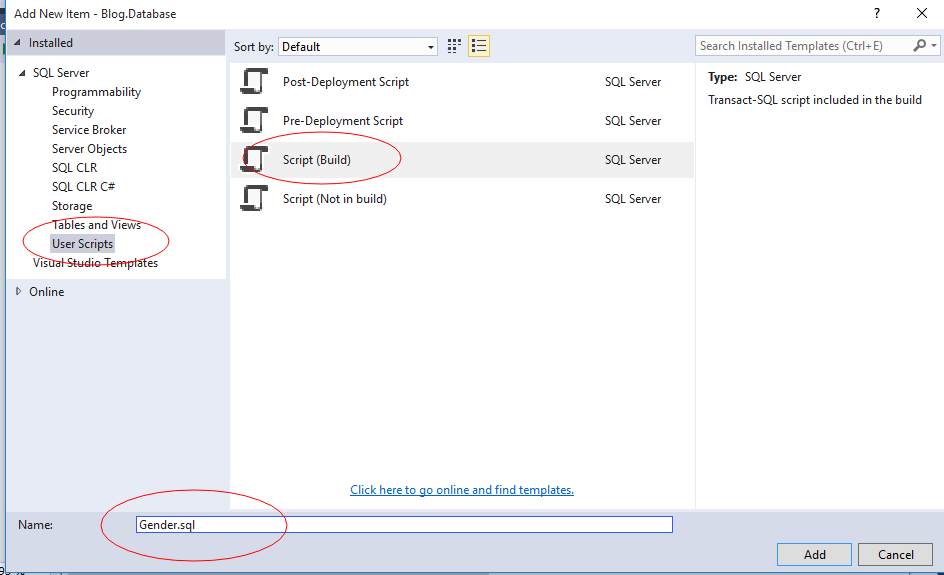
3、(重要)此时要在Gender.sql右键,Builder Action-None,否则无法编译

4、在Gender.sql添加下面的Sql,这个sql在每次部署的时候都要执行,所以一定是“幂等”的:
PRINT ‘Beginning Deployment Gender table...‘ IF EXISTS (select top 1 1 from dbo.Gender where Value=‘01‘) update dbo.Gender set Name=‘Male‘ where Value=‘01‘ else insert dbo.Gender(value,Name) values(‘01‘,‘Male‘) IF EXISTS (select top 1 1 from dbo.Gender where Value=‘02‘) update dbo.Gender set Name=‘Female‘ where Value=‘02‘ else insert dbo.Gender(value,Name) values(‘02‘,‘Female‘) IF EXISTS (select top 1 1 from dbo.Gender where Value=‘03‘) update dbo.Gender set Name=‘Unknown‘ where Value=‘03‘ else insert dbo.Gender(value,Name) values(‘03‘,‘Unknown‘) PRINT ‘Finishing Deployment Gender table...‘
5、在Script.PostDeployment.sql中编写下面的脚本:
PRINT ‘Running Post-Deploy Scripts‘ :r .\Gender.sql --append other sql scripts PRINT ‘End Post-Deploy Scripts‘
6、Compare-Update,将此更改更新到本地数据库
此时你会发现本地数据库添加了Gender表,但是我们添加的三条数据并没有进来,这是因为Script.PostDeployment.sql并没有执行,这个脚本只有在发布的时候才能执行。
七、添加publish文件
通过上面的步骤我们可以看出来,我们每次都是先更改数据库迁移解决方案,然后通过Compare和Update操作将更新同步到本地,但是这样操作存在两个缺点:
1、Script.PostDeployment.sql并没有执行,无法将ReferenceData同步在数据库
2、只适用于同步本地数据库,其他环境需要采用一些自动化的方式来完成,而不是手工compare,update,避免人工操作失误
通过下面的步骤来添加publish文件
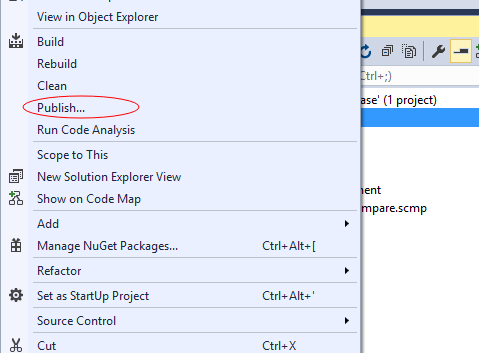
1、在Blog.Database工程上右键-publish
接下来要添加数据库连接,然后添加Create Profile,最后点击publish。
通过Create Profile添加了一个xml的publish文件,重命名为:Local.publish.xml。
我们可以通过双击此xml文件完成对本地数据库的publish操作
八、自动化publish数据库迁移方案到其他数据库环境
我们通过手工publish将更改应用到本地,但是其他环境(Dev,QA,Staging,Prod)则要通过脚本来完成。
1、在本地新建一个空数据库Blog_QA用来模拟QA的数据库环境
2、采用之前的步骤新建一个publish文件,该publish文件的数据库为Blog_QA,将该xml文件重命名为:Blog_QA.publish.xml
在Blog_QA.publish.xml右键,属性,Copy To Output Directory:Copy Always
3、通过sqlpackage程序要迁移数据库
运行命令行:cd 到C:\Program Files (x86)\Microsoft SQL Server\110\DAC\bin目录
执行命令:SqlPackage.exe /Action:Publish /SourceFile:G:\SourceCode\Blog.Database\bin\Debug\Blog.Database.dacpac
/Profile:G:\SourceCode\Blog.Database\bin\Debug\Publish\Blog_QA.publish.xml
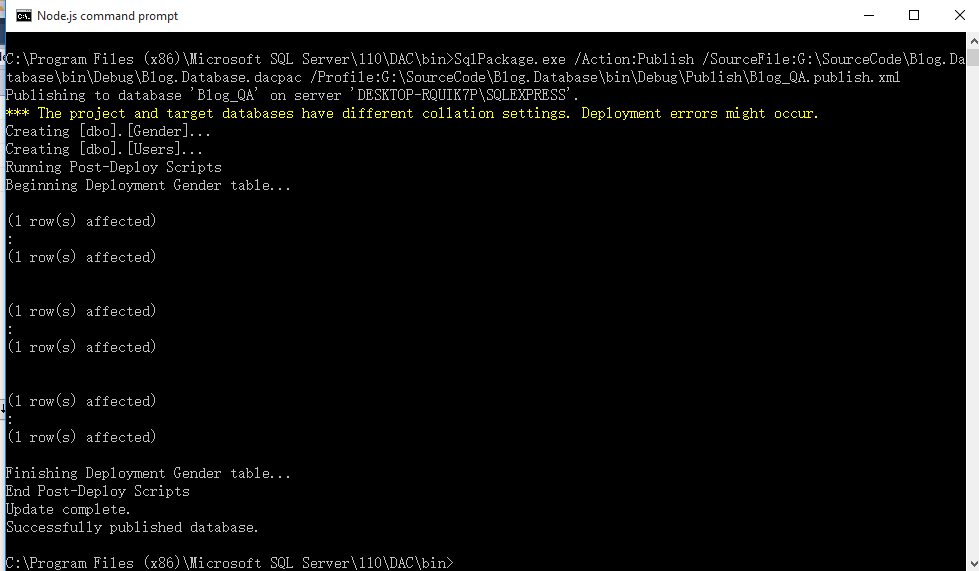
通过编写脚本来完成不同环境的数据库迁移。
该方案的核心在于:所有开发人员通过维护vs数据库工程来完成对数据库的更改,最后通过publish工具来完成数据库迁移,同时我们可以通过sqlpackage工具来完成自动化迁移。
整个demo提供下载:https://git.oschina.net/richieyangs/Blog.Database.git
由于数据库连接字符串的不同,所以不能直接使用demo中的publish文件来完成数据库迁移。大家根据自己的情况做出修改。