大型网站技术基石篇-容器Docker与kubernetes
Docker和Kubernetes的关系就如Xen与OpenStack。
Docker是一种容器技术,和Hypervisor(KVM/Xen这类)不同的是,Docker不会提供一整个操作系统,他能提供隔离的程序运行环境。对一个应用来说这已经够了。
Kubernetes是Google的一个开源容器管理项目,他能利用Docker/其他技术部署/管理容器集群。
Docker
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,与KVM这类超级底层虚拟化方案相比,Docker是一种轻量级虚拟化方案,他不需要对内核进行改变,他主要利用linux内核特性实现虚拟化,所有容器运行在同一个内核中。另外,docker还可以部署在KVM/XEN这类虚拟机中! 容器与虚拟机对比如下图。
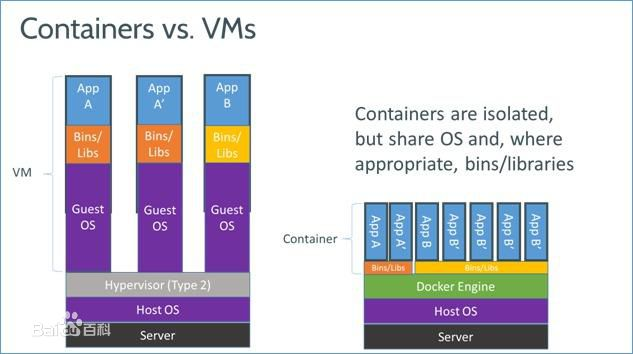
Docker的架构
Docker使用客户端-服务器(client-server)架构模式。Docker客户端会与Docker守护进程进行通信。Docker守护 进程会处理复杂繁重的任务,例如建立、运行、发布你的Docker容器。Docker客户端和守护进程可以运行在同一个系统上,当然你也可以使用 Docker客户端去连接一个远程的Docker守护进程。Docker客户端和守护进程之间通过socket或者RESTful API进行通信。

Docker重要概念
镜像(Image)
Docker镜像是一个只读的模板。举个例子,一个镜像可以包含一个运行在Apache上的Web应用和其使用的Ubuntu操作系统。镜像是用来创建容器的。Docker提供了简单的,你也可以下载别人已经创建好的镜像。
仓库(Image)
Docker仓库用来保存镜像。其相当于一个代码仓库,同样的,Docker仓库也有公有和私有的概念。公有的Docker仓库名字是Docker Hub。也可以自己创建仓库。
容器(Container)
一个Docker容器包含了某个应用运行所有的所需要的环境。每一个Docker容器都是从Docker镜像创建 的。Docker容器可以运行、开始、停止、移动和删除、保存为镜像。每一个Docker容器都是独立和安全的应用平台。
Docker内部采用Linux的命名空间机制实现隔离性,采用cgroup实现资源的划分(例如给容器划分2G内存、0.5个cpu)。
隔离-命名空间介绍
命名空间是为操作系统层面的虚拟化机制提供支撑,目前实现的有六种不同的命名空间,分别为mount命名空间、UTS命名空间、IPC命名空间、用户命名空间、PID命名空间、网络命名空间。命名空间简单来说提供的是对全局资源的一种抽象,将资源放到不同的容器中(不同的命名空间),各容器彼此隔离。命名空间有的还有层次关系,如PID命名空间,图 为命名空间的层次关系图。可以简单理解为像C++,java那样的命名空间。
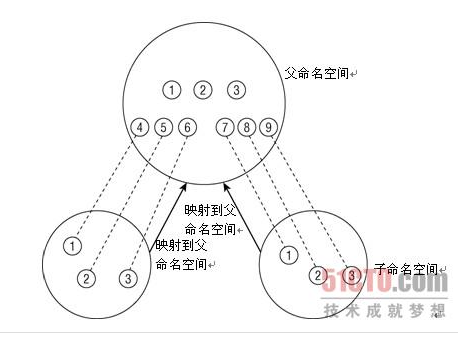
资源划分-cgroup介绍
cgroup就是controller group,最初由google的工程师提出,后来被整合进Linux内核中,它为Linux内核提供了一种任务聚集和划分的机制,通过一组参数集合将一些任务组织成一个或多个子系统。 cgroup能限制某个或者某些进程的分配资源。也就是能完成一组容器的概念,在这个容器中,有分配好的特定比例的cpu时间,IO时间,可用内存大小等。Cgroups是实现IaaS虚拟化(kvm、lxc等),PaaS容器沙箱(Docker等)的资源管理控制部分的底层基础。
子系统是根据cgroup对任务的划分功能将任务按照一种指定的属性划分成的一个组,主要用来实现资源的控制。在cgroup中,划分成的任务组以层次结构的形式组织,多个子系统形成一个数据结构中类似多根树的结构。cgroup包含了多个孤立的子系统,每一个子系统代表单一的资源。
Docker示例
在安装docker之后,运行其守护进程,然后就可以使用docker创建运行容器。安装docker可以百度一下。
运行docker命令,显示信息就表示安装成功。最好内核是3.8以后的。
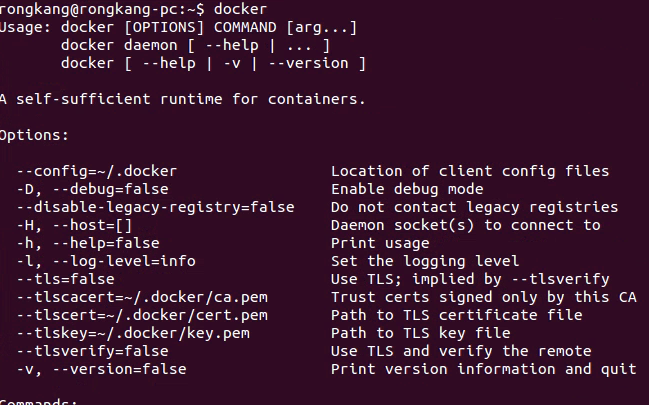
1. 采用docker pull命令从公共库中拉取(下载)一个镜像到我的电脑上。

2. 采用docker run命令,可以指定一个镜像作为基础运行容器。 我这里指定了ubuntu镜像,因为我电脑中没有ubuntu镜像,他会自动从公共仓库下载ubuntu的镜像。仔细瞧的话,可以看出我进入了该容器的bash程序。

3. 输入docker images,可以查看主机上存储的镜像。

Docker也提供了很多方便的命令对镜像进行操作。
kubernetes
项目主页:http://kubernetes.io/
docker仅能在单机上部署容器,而kubernetes可以统一管理各类容器,形成集群。Kubernetes作为Docker生态圈中重要一员,是Google多年大规模容器管理技术的开源版本。Kubernetes支持GCE、vShpere、CoreOS、Azure等平台,也可以直接运行在物理机上。
Kubernetes非常适合做微服务的架构。
其主要功能如下:
1) 用户不需要关心需要多少台机器,只需要关心软件(服务)运行所需的环境。以服务为中心,你需要关心的是api,如何把大服务拆分成小服务,如何使用api去整合它们。
2) 以集群的方式运行管理容器。
3) 解决Docker跨机器容器之间的通讯问题。
4) Kubernetes的Pods自我修复机制使得容器集群总是运行在用户指定的状态。
Kubernetes有几个重要的概念:
1. Pod
Kubernetes的容器管理的最小单位不是容器,貌似说的很别扭。 就是容器并不是Kubernetes管理的最小单元,而是Pods,
一个Pod包含一个或者多个容器。例如一个小程序有数据库和后台程序,可以分别放到一个容器里面,这两个容器组成一个Pods。
Pod的YAML 描述方式:


运行如下命令就会创建Pod:
kubectl create -f ./hello-world.yaml
运行如下命令就会查看Pod状态:
$ kubectl get pods
2. minion/node
minion和node的意思是一样的,是一个主机节点的意思。例如一个虚拟机、一个物理主机。注意,一个Pod不会跨越node。就是即使一个Pod有多个容器,里面的容器会同时存在在同一个Node中,不会分别在不同的Node中。 Kubernetes的调度器会根据Pod的资源需求定义来将Pod分配到不同的Node中(如今支持定义CPU需求、内存需求)。Kubernetes的master/slave程序运行在node里面。
3. Replication Controller
Replication 是复制的意思,用来解决Pod的线性扩容缩容问题,Replication Controller可以创建一个pod的多个副本,并且可以保证集群中该Pod的副本数量保持平衡。例如副本数量规定为10,如果某个pod挂了,数量变为9,那么Replication Controller会自动创建一个Pod,恢复到10个副本的水平。 多个副本可以在不同的Node中。
Replication Controller的YAML 描述方式:


replicas表示副本的数量
template是对Pod的描述。ReplicationController根据template创建多个Pod(数量=replicas),标签为app: nginx。
运行如下命令就会创建Replication Controller: kubectl create -f ./nginx-rc.yaml
4. Service
Service用来解决Pod的服务发现问题,因为Pod的运行状态可以动态变化(机器切换、宕机),所以访问端最好不要直接去访问某个Pod,而是通过service,service能够将请求进行转发。
服务的YAML描述如下:


该定义创建了一个服务,会将标签为app:nginx(selector选的)的Pod纳入服务中,也就是说该服务接收到的请求会转发给标签为app: nginx的Pod处理。注意:service是负载均衡的,会自动分配请求给不同的Pod。有没有觉得很方便?把Serivce暴露给客户端,客户端只需要请求service,不需要知道后台是个集群。
运行如下命令就会创建Service:
kubectl create -f ./nginx-rc.yaml
5. Label
标签,用来做逻辑上的标记。用来关联service、replication controller和pod.
Kubernetes架构
下图为官方的架构图。

从图中看出,Kubernetes的架构是典型的master/Slave架构。
Master负责总体的协调控制,Slave负责具体的任务。Master/Slave的组件如下:

盗个图,下图能更清晰的展示Kubernates。

持续更新~~~
转载请注明出处:http://www.cnblogs.com/stonehat/p/5148455.html