虽然这次的主题是异常,但是说的更确切点应该叫程序是如何运行的。
编程语言是在计算机的内存中运行起来的,然而运行的时候,无论是基于jvm的java、scala之类的语言,还是像C/C++这样直接跟操作系统打交道的语言,都会将得到的内存分为几个区域,每个区域负责不同的事情。
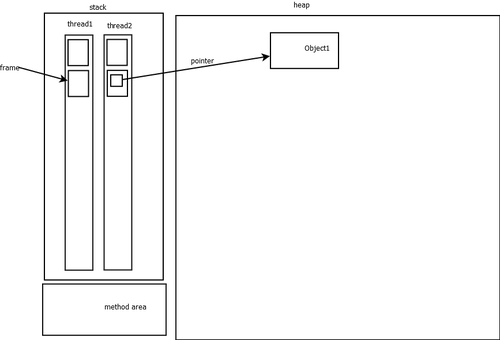
大体上程序内存被分为这样的几个区域:
堆(heap):malloc、new 这样的关键字生成的对象都会利用这个区间的内存;当然jvm中堆会被进一步的细分为老年代、新生代,新生代又有伊甸园、幸存者,这个以后有时间专门介绍;
栈(stack):这块主要是给线程使用的,当线程调用一个方法的时候,就会有一个栈帧(frame)入栈,正常情况下方法执行结束,对应的frame出栈,再调用的新的frame入栈;
方法区:差不多就是程序员写的代码被编译成机器码之后就会存放在这里了,hotspot在java8中已经弃用方法区改为metastore,主要的区别好像就是gc变得容易了。
当然还有其他很多区域,这里就不一一介绍了,以上几个区域的关系大概如下图
下面回归正题介绍异常:
异常的大概形式大家应该都很熟了,try、catch、finally在加上不太常用的throw、throws,这里就不介绍了。大概差不多是像下面这么使用的:

来分析一下发生异常的时候执行method2的线程的栈的使用情况:
1.首先method2对应的栈帧(frame2)入栈;
2.执行method1即method1对应的栈帧(frame1)入栈;
3.如果method1成功执行,则frame1出栈,接着method2执行成功,method2对应的frame2出栈,线程结束;如果method1抛出异常,首先构建异常对象e,frame1出栈,接着找当前上下文有没有对应的处理异常的语句(即执行method1的时候有没有对应的exception的catch语句),发现没有,所以到上一层即method2的上下文中查找,发现刚好有;
4.catch对应的代码块其实也可以看成一个参数是异常e的引用的方法了(就像public void catch(Execption e)),对应的catch frame入栈,执行e.printStackTrace()。
根据上面的分析,可以看出,如果不会发生异常,即使写了try、catch对程序的效率应该也没有影响;发生异常最大的影响在于要构造对应的异常对象,并且要不断地向上回归找取处理异常的catch方法。
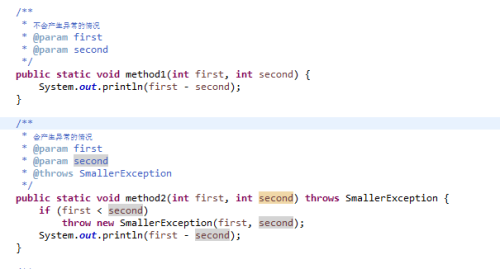
现在假设有这么一个场景,需要做两个整数的减法,假设我们现在还是小学生不知道什么叫做负数,那么当被减数小于减数的时候,我们就不知道该怎么处理了,这就是一种异常了,所以定义如下异常。

接着定义了两个处理减法操作的方法,一个用作对比不抛出异常(method1),一个是我们观察的重点要抛出异常(method2):
在以下四种场景下调用1000次减法操作:
1.调用1000次的method1,这个时候根本没有异常;
2.在保证被减数更大的情况下调用1000次method2,这个时候不会抛出异常;
3.在保证被减数更小的情况下调用1000次method2,这个时候一定抛出异常;
4.在保证被减数更小的情况下调用1000次method2,而调用method2的函数不直接处理异常(没有对应的catch块),这个时候一定抛出异常而且按道理会比第三种情况要慢;
以下是十次试验之后的结果对比:

虽然实验次数不太多,但是结果还是比较明显的,在没有真正发生异常的时候,程序效率不会明显下降;但是如果真的发生了异常对异常的处理带来了额外的开销,而且捕捉的越不及时开销越大。
相关代码已经打包上传,欢迎大家指处不足。
2017.2.5
明天要上班 /(ㄒoㄒ)/~~