Mahout中对协同过滤算法进行了封装,看一个简单的基于用户的协同过滤算法。
基于用户:通过用户对物品的偏好程度来计算出用户的在喜好上的近邻,从而根据近邻的喜好推测出用户的喜好并推荐。

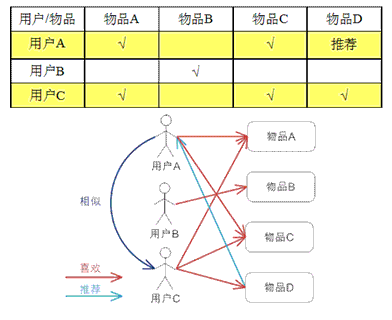{kind=link}
程序中用到的数据都存在MySQL数据库中,计算结果也存在MySQL中的对应用户表中。
package com.mahout.helloworlddemo;
import java.sql.Connection;
import java.sql.DatabaseMetaData;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.HashSet;
import java.util.List;
import org.apache.mahout.cf.taste.impl.model.jdbc.MySQLJDBCDataModel;
import org.apache.mahout.cf.taste.impl.neighborhood.NearestNUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.model.JDBCDataModel;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.recommender.Recommender;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
import com.mahout.util.DBUtil;
import com.mysql.jdbc.jdbc2.optional.MysqlDataSource;
/**
*
*@author wxisme
*@time 2015-9-13 下午6:25:26
*/
public class RecommenderIntroFromMySQL {
public static void main(String[] args) throws Exception {
//连接MySQL
MysqlDataSource dataSource = new MysqlDataSource();
dataSource.setServerName("localhost");
dataSource.setUser("root");
dataSource.setPassword("1234");
dataSource.setDatabaseName("mahoutdemo");
//获取数据模型
JDBCDataModel dataModel = new MySQLJDBCDataModel(dataSource, "taste_preferences", "user_id", "item_id", "preference","time");
DataModel model = dataModel;
//计算相似度
UserSimilarity similarity = new PearsonCorrelationSimilarity(model);
//计算阈值
UserNeighborhood neighborhood = new NearestNUserNeighborhood(2,similarity,model);
//推荐
Recommender recommender = new GenericUserBasedRecommender(model,neighborhood,similarity);
Connection con = DBUtil.getConnection();
Statement stmt = con.createStatement();
//获取每个用户的推荐数据并存入数据库
for(int i=0; i<5; i++) {
List<RecommendedItem> recommendations = recommender.recommend(i, 3);
String tableName = "user_" + i;
for (RecommendedItem recommendation : recommendations) {
//如果是第一次推荐就创建该用户的数据表
if(!doesTableExist(tableName)) {
String createSQL = "create table " + tableName
+ " (item_id bigint primary key,value float);";
stmt.execute(createSQL);
}
String insertSQL = "insert into " + tableName + " values ("
+ recommendation.getItemID() + "," + recommendation.getValue() + " );";
//插入用户的推荐数据
stmt.execute(insertSQL);
System.out.println(recommendation);
}
}
}
/**
* 是否存在这个数据表
* @param tablename
* @return
* @throws SQLException
*/
public static Boolean doesTableExist(String tablename) throws SQLException {
HashSet<String> set = new HashSet<String>();
Connection con = DBUtil.getConnection();
DatabaseMetaData meta = con.getMetaData();
ResultSet res = meta.getTables(null, null, null,
new String[]{"TABLE"});
while (res.next()) {
set.add(res.getString("TABLE_NAME"));
}
DBUtil.close(res, con);
return set.contains(tablename);
}
}
测试数据:
1,101,5
1,102,3
1,103,2.5
2,101,2
2,102,2.5
2,103,5
2,104,2
3,101,2.5
3,104,4
3,105,4.5
3,107,5
4,101,5
4,103,3
4,104,4.5
4,106,4
5,101,4
5,102,3
5,103,2
5,104,4
5,105,3.5
5,106,4
运行结果:

更多Mahout和协同过滤算法的介绍与分析:
http://www.cnblogs.com/dlts26/archive/2011/08/23/2150225.html
http://www.tuicool.com/articles/FzmQziz
http://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/
时间: 2024-08-02 23:12:20