引言
在模式识别中,经常碰到协方差矩阵这个概念,以前一直没搞懂,现在又碰到这个破玩意了,决定把他搞懂,下面就是做的笔记,与大家分享一下
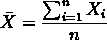
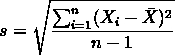
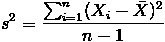
均值描述的是样本集合的样本的平均值,即平均水平.
标准差给我们描述的则是样本集合的各个样本点到均值的平均距离,反映的是与平均值的偏离程度。反映了数据的稳定程度。

之所以除以n-1而不是除以n,是因为这样能使我们以较小的样本集更好的逼近总体的标准差,即统计上所谓的“无偏估计”。
比如:一批灯泡,要考察期寿命,我们需要考察两个量,均值和方差,均值只能表示平均寿命,但还不能反映这批灯泡的稳定性,稳定性需要用方差来衡量。
这里的x只是一维的情况,我们可以将x这一维想象成person(name,age,height)这个特征向量中的age这个特征,特别注意,x不是代表了person这个样本,如果代表的是一个person那么age,height的平均值有什么意义呢?
为什么需要协方差?
均值和方差一般是用来描述一维数据的,但现实生活我们常常遇到含有多维数据的数据集
多维情况下,处理需要E(X)和D(X)外,还需要讨论各个维度之间的关系,协方差就是这样一种用来度量两个随机变量(特征)相关性的统计量(特征选取的时候我们需要选择相关性小的特征,如NB算法),方差是协方差的一种特殊情况,即当两个变量是相同的情况。期望值分别为E[x]与E[Y]的两个实数随机变量x与Y之间的协方差定义为:


协方差也只能处理二维问题,当维数多了,就需要采用协方差矩阵的形式:
协方差矩阵
定义:

举一个简单的三维的例子,假设数据集有
 三个维度,则协方差矩阵为
三个维度,则协方差矩阵为C= cov(x,x),cov(x,y),cov(x,z)
cov(y,x),cov(y,y),cov(y,z)
cov(z,x),cov(z,y),cov(z,z)
可见,协方差矩阵是一个对称的矩阵,而且对角线是各个维度上的方差。
协方差矩阵计算的是不同维度之间的协方差,而不是不同样本之间的。
Matlab协方差示例
随机产生一个10*3维的整数矩阵作为样本集,10为样本的个数,3为样本的维数
sample = fix(rand(10,3)*50)
结果:

前面我们也特别强调了,协方差矩阵是计算不同维度(不同特征)间的协方差,要时刻牢记这一点。样本矩阵的每行是一个样本,每列为一个维度,所以我们要按列计算均值。为了描述方便,我们先将三个维度的数据分别赋值:

- 1. 计算三者的两两之间的协方差:
dim1与dim2,dim1与dim3,dim2与dim3的协方差:
●sum((dim1-mean(dim1)) .* (dim2-mean(dim2)) ) / ( size(sample,1)-1 )%
78
●sum((dim1-mean(dim1)) .* (dim3-mean(dim3)) ) / ( size(sample,1)-1 )%-120.2444
●sum((dim2-mean(dim2)) .* (dim3-mean(dim3)) ) / ( size(sample,1)-1 )%-126.9444 - 2. 计算对角线各个维度上的方差
std(dim1)^2 %得到:301.1556
std(dim2)^2 %得到:268.9444
std(dim3)^2 %得到:216.0111
这样,我们就得到了计算协方差矩阵所需要的所有数据 - 3. 调用Matlab自带的cov函数进行验证:
cov(sample)
结果:

跟我们计算的结果一直,说明计算结果是正确的。
最后,理解协方差矩阵
★关键就在于牢记它计算的是不同维度之间的协方差,而不是不同样本之间,拿到一个样本矩阵,我们最先要明确的就是一行是一个样本还是一个维度
★意义:随机变量之间的相互关系