介绍一下linux内核中的哈希散列表的实现,在linux内核中哈希散列表(hash list)用的非常的多,
并且自己以后在做软件设计的时候,也非常有可能用到。毕竟,哈希散列表在数据的查找过程中非常的方便。
linux内核对哈希散列表的实现非常的完美,所以非常有必要学习一下。
在哈希散列表的实现过程中,用到的两个非常有用的结构体:
哈希散列表头结构体 :
struct hlist_head
{
struct hlist_node *first;
}
哈希散列表的节点结构:
struct hlist_node
{
struct hlist_node *next;
struct hlist_node **pprev;
}
内核中的哈希散列表的组织结构图: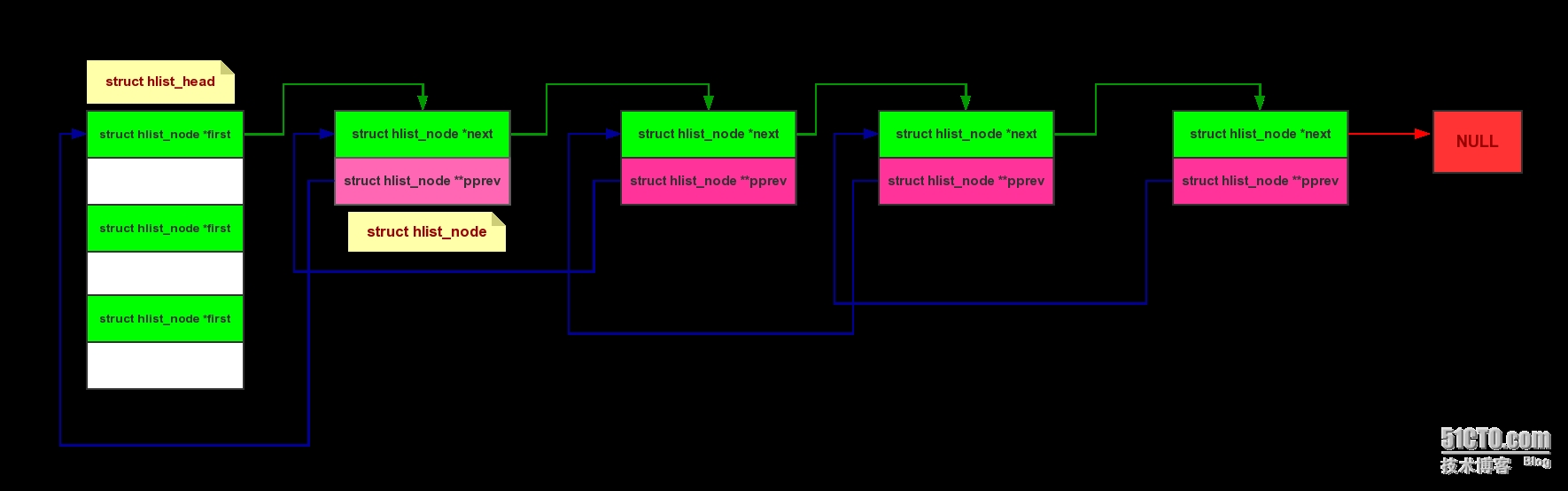
至于内核中为什么没有将哈希散列表的头节点(struct hlist_head)定义成跟struct hlist_node一样的形式。
内核中的解释是这样的:应为哈希散列表在内核中使用的非常多,将头节点定义称struct hlist_head {struct hlist_node *first}能节省一半的内存空间。
而为了实现对哈希散列表中的所有节点都采取同样的操作方式,而不需要将哈希散列表的头节点作为例外来处理。所以对struct hlist_node中定义了struct hlist_node **pprev这样的成员。
struct hlist_node 结构体中的 pprev成员的作用:用于指向当前struct hlist_node节点的前一个 struct hlist_node结构体的 next成员。
1.哈希散列表头节点的定义以及初始化:
#define HLIST_HEAD(name) \
struct hlist_head name = {.first = NULL}
2.哈希散列表头的初始化:
#define HLIST_HEAD_INIT(ptr) ( (ptr)->first = NULL )
3.哈希散列表的数据节点的初始化:
static inline void hlist_node_init(struct hlist_node *node)
{
node->next = NULL;
node->pprev = NULL;
}
4.判断一个哈希散列表是否为空:
int hlist_empty(struct hlist_head *head)
{
return !head->first;
}
5.判断一个哈希节点是否哈希散列表的哈希链表之中:
int hlist_unhash( struct hlist_node *node )
{
return !node->pprev; // 如果node->pprev为空,则表明 node不在哈希链路之中
}
6.从哈希链路中删除一个节点:
void __hlist_del( struct hlist_node *node )
{
struct hlist_node *next = node->next;
struct hlist_node **pperv = node->pperv;
if(next)
next->pprev = pperv;
*pperv = next ; //或 *(node->pprev) = next;
}
在删除哈希链路中的节点元素时,需要考虑删除的元素是否是链路中的末尾元素。
7.从哈希链路中删除一个节点然后并对其进行初始化:
void __hlist_node_init( struct hlist_node *node )
{
if( !hlist_unhash(node) )
__hlist_del(node)
hlist_node_init(node);
}
8.在哈希链表头部后面添加一个节点元素:
void hlist_add_head(struct hlist_head *head, struct hlist_node *new )
{
new->next = head->first;
new->pprev = &(head->first);
if( !hlist_empty(head) )
head->first->pprev = &(new->next);
head->first = new;
}
须知:在往哈希链路中头后添加节点是需要考虑的是:要加入的节点是否是第一个节点元素
9.往哈希链路中的某个节点后面添加一个节点:
void hlist_add_after(struct hlist_node *node, struct hlist_node *new)
{
struct hlist_node *tmp = node->next;
new->next = tmp;
new->pprev = &(node->next);
node->next = new;
if(tmp)
tmp->pprev = &(new->next);
}
10.往哈希链路中的某个节点前面添加一个节点:
void hlist_add_before( struct hlist_node *node, struct hlist_node *new )
{
struct hlist_node **tmp = node->pprev;
new->next = node;
new->pperv = node->pprev;
*tmp = new;
node->pprev = &(new->next);
}
11.把一个哈希链路从一个头节点移动到另一个头节点上:
void hlist_move_list(struct hlist_head *old, struct hlist_head *new)
{
struct hlist_node *tmp = old->first;
new->first = tmp;
if(tmp)
tmp->pprev = &(new->first);
old->first = NULL;
}
对哈希散列表中的元素进行遍历的方法:
对每个struct hlist_node{}结构体进行遍历:
//pos用于存放每个struct hlist_node结构体的地址;
// head : 哈希散列表的头节点;
1.#define hlist_for_each(pos, head) \
for(pos = (head)->first ; pos != NULL ; pos = pos->next)
2.#define hlist_for_each_safe(pos, tmp, head) \
for( pos = (head)->first, tmp = pos->next; \
pos != NULL; \
pos = tmp, tmp = pos->next)
对哈希散列表中的每个元素进行遍历:
// ptr :是struct hlist_node 结构体的地址;
// member : 是struct hlist_node 结构体嵌入到其他结构体中的成员名;
// type : 是strcut hlist_node 结构体嵌入的结构体的类型;
1. #define hlist_entry(ptr, member, type) \
container_of(ptr, type, member)
hlist_entry()用于求出struct hlist_node结构体所嵌入的结构体的地址;
// pos : 用于存放struct hlist_node结构体嵌入的结构体的地址;
// node : 用于存放哈希链路中的下一个struct hlist_node 结构体的地址;
// head : 哈希散列表的头节点;
// member: struct hlist_node 在大的结构体中的成员名;
2. #define hlist_for_each_entry(pos, node, head, member) \
for((node) = head->first; \
(node) != NULL && pos = hlist_entry(node, member, typeof(*pos)); \
(node) = (node)->next )
// 从 struct hlist_node *node 节点之后开始继续遍历;
3.#define hlist_for_each_entry_continue(pos, node, member) \
for((node) = (node)->next ; \
(node) != NULL && pos = hlist_entry(node, member, typeof(*pos) ) ; \
(node) = (node)->next )
//从 struct hlist_node *node 开始继续遍历;
4. #define hlist_for_each_entry_from(pos, node, member) \
for( ; \
(node) != NULL && pos = hlist_entry(node, member, typeof(*pos) ); \
(node) = (node)->next )
// hlist_for_each_entry_safe()函数用于在遍历链路的同时,删除某个元素。
// pos :用于存放链路中元素的地址;
// node :用于存放链路中的struct hlist_node 结构体的地址;
// tmp :用于缓存链路中下一个struct hlist_node 结构体的地址;
// head : 哈希散列表的链表头节点; struct hlist_head;
// member : struct hlist_node 结构体在大的结构体中成员名;
5. #define hlist_for_each_entry_safe(pos, node, tmp, head, member)
for( (node) = (head)->first ; \
(node) != NULL && (tmp) = (node)->next &&
pos = hlist_entry(node, member, typeof(*pos) ); \
(node) = (tmp) )
以上这些对哈希散列表的操作函数,是我根据内核中对哈希散列表的各种操作写的,基本的做法都源于 /include/linux/list.h文件。