一:MongoDB的简介:
MongoDB是一个高性能,开源,无模式的文档型数据库,是当前NoSql数据库中比较热门的一种。它在许多场景下可用于替代传统的关系型数据库或键/值存储方式。而且可以很容易的和JSON类的数据结合,他不支持事务,但支持自动分片功能,这对大数据的分布式存储有着十分重要的作用。
二:MongoDB的索引类型:
单字段索引:
组合索引(多字段索引):对多个key做索引
多键索引:对key和value中的key做索引
空间索引:基于位置做索引
文本索引:全文搜索
hash索引:仅支持精确值查找
稀疏索引(sparse):不为每一个值做索引,一般得是顺序排放才可以做稀疏索引
三:MongoDB的复制功能:
MongoDB有两种复制类型:Master/Slave主从和replica set副本集复制,但是由于MongoDB的特性,主从复制架构已经基本放弃,比较常见的就是副本集复制方式
replica set的工作特性:
1,复制集可以实现自动转移 heartbeat超时,自动失效转移(通过选举方式实现)
2,至少有3个节点,且奇数个节点,可以使用arbiter来参与选举
复制集中的特殊类型的节点分类:
0优先级的节点:冷备节点,不会被选举成为主节点,但可以参与选举
被隐藏的从节点:首先是一个0优先级的从节点,拥有选举权,不会被客户端直接访问到
延迟复制的从节点:是一个0优先级的从节点,不能被选为主节点,且复制时间落后与主节点一个固定的时长。
arbiter:仲裁者,没有数据,不可能成为主节点。
实验内容:
一,实现MongoDB数据的复制
实验模型:

实验环境:
node1:172.16.18.1 MongoDB centos6.5
node2:172.16.18.2 MongoDB centos6.5
node3:172.16.18.3 MongoDB centos6.5
实验内容:
首先要确定各节点的时间一致
1.1 MongoDB安装:分别在node1,node2,node3节点安装一下三个包
mogodb安装需要:一下三个包
mongodb-org-shell-2.6.4-1.x86_64.rpm
mongodb-org-tools-2.6.4-1.x86_64.rpm
mongodb-org-server-2.6.4-1.x86_64.rpm
编辑服务器的配置文件,/etc/mongod.conf
logpath=/var/log/mongodb/mongod.log #日志的路径 logappend=true #开启日志 fork=true #port=27017 #默认监听的端口 #dbpath=/var/lib/mongo #默认的数据路径 dbpath=/mongodb/data #自定义的数据路径 pidfilepath=/var/run/mongodb/mongod.pid #bind_ip=127.0.0.1 #定义绑定IP,也就是监听那些IP可来链接服务器,注销是允许所有。 httpinterface=true #开放web页面, rest=true replSet=testset replIndexPrefetch=_id_only
配置好后将配置分别发送到其他两个节点,并创建数据目录,修改权限
mkdir /mongodb/data/ -pv
chown -R mongod.mongod /mongodb/
全部启动:可能启动会比较慢,那是因为要初始化数据
1.2链接到数据库
[[email protected] ~]# mongo
MongoDB shell version: 2.6.4
connecting to: test
> rs.status()
{
"startupStatus" : 3,
"info" : "run rs.initiate(...) if not yet done for the set",
"ok" : 0,
"errmsg" : "can‘t get local.system.replset config from self or any seed (EMPTYCONFIG)"
}
使用rs.status()查看状态,有3个节点,但是都没有初始化配置。需要运行rs.initiate()
1.3运行rs.initiate()
> rs.initiate()
{
"info2" : "no configuration explicitly specified -- making one",
"me" : "node2.aolens.com:27017",
"info" : "Config now saved locally. Should come online in about a minute.",
"ok" : 1
}
testset:OTHER> rs.status()
{
"set" : "testset",
"date" : ISODate("2014-10-12T07:51:58Z"),
"myState" : 1,
"members" : [
{
"_id" : 0,
"name" : "node2.aolens.com:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 920,
"optime" : Timestamp(1413100302, 1),
"optimeDate" : ISODate("2014-10-12T07:51:42Z"),
"electionTime" : Timestamp(1413100302, 2),
"electionDate" : ISODate("2014-10-12T07:51:42Z"),
"self" : true
}
],
"ok" : 1
}
testset:PRIMARY>
可以看到添加了一个节点node2,也就是自己,且是primary节点。以及所有的状态
1.4添加其他两个节点
testset:PRIMARY> rs.add("node1.aolens.com")
{ "ok" : 1 }
testset:PRIMARY> rs.add("node3.aolens.com")
{ "ok" : 1 }
用rs.status()查看
testset:PRIMARY> rs.status()
{
"set" : "testset",
"date" : ISODate("2014-10-12T08:03:48Z"),
"myState" : 1,
"members" : [
{
"_id" : 0,
"name" : "node2.aolens.com:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 1630,
"optime" : Timestamp(1413101019, 1),
"optimeDate" : ISODate("2014-10-12T08:03:39Z"),
"electionTime" : Timestamp(1413100302, 2),
"electionDate" : ISODate("2014-10-12T07:51:42Z"),
"self" : true
},
{
"_id" : 1,
"name" : "node1.aolens.com:27017",
"health" : 1,
"state" : 5,
"stateStr" : "STARTUP2",
"uptime" : 17,
"optime" : Timestamp(0, 0),
"optimeDate" : ISODate("1970-01-01T00:00:00Z"),
"lastHeartbeat" : ISODate("2014-10-12T08:03:46Z"),
"lastHeartbeatRecv" : ISODate("2014-10-12T08:03:47Z"),
"pingMs" : 224
},
{
"_id" : 2,
"name" : "node3.aolens.com:27017",
"health" : 1,
"state" : 6,
"stateStr" : "UNKNOWN",
"uptime" : 8,
"optime" : Timestamp(0, 0),
"optimeDate" : ISODate("1970-01-01T00:00:00Z"),
"lastHeartbeat" : ISODate("2014-10-12T08:03:47Z"),
"lastHeartbeatRecv" : ISODate("1970-01-01T00:00:00Z"),
"pingMs" : 905,
"lastHeartbeatMessage" : "still initializing"
}
],
"ok" : 1
}
有没有发现新加的这两个节点状态不对?没有关系,可能是还没有同步过来,稍等在刷新试试
"name" : "node1.aolens.com:27017",
"stateStr" : "SECONDARY",
"name" : "node3.aolens.com:27017",
"stateStr" : "SECONDARY",
再刷新时添加的两个节点都成为了secondary。
1.5我们在主节点来创建一些数据
testset:PRIMARY> use test
switched to db test
testset:PRIMARY> for (i=1;i<=1000;i++) db.students.insert({name:"student"+i,age:(i%100)})
WriteResult({ "nInserted" : 1 })
连接到从节点来看一下
[[email protected] ~]# mongo
MongoDB shell version: 2.6.4
connecting to: test
Welcome to the MongoDB shell.
For interactive help, type "help".
For more comprehensive documentation, see
http://docs.mongodb.org/
Questions? Try the support group
http://groups.google.com/group/mongodb-user
testset:SECONDARY> use test
switched to db test
testset:SECONDARY> show collections
2014-10-11T14:52:57.103+0800 error: { "$err" : "not master and slaveOk=false", "code" : 13435 } at src/mongo/shell/query.js:131
#提示需要不是主节点,没有slaveOK不让查看,那么便在当前节点指定slaveOK,便可以了
testset:SECONDARY> rs.slaveOk()
testset:SECONDARY> show collections
students
system.indexes
可以使用rs.isMaster()查询主节点是谁
testset:SECONDARY> rs.isMaster()
{
"setName" : "testset",
"setVersion" : 3,
"ismaster" : false,
"secondary" : true,
"hosts" : [
"node1.aolens.com:27017",
"node3.aolens.com:27017",
"node2.aolens.com:27017"
],
"primary" : "node2.aolens.com:27017", #主节点是谁
"me" : "node1.aolens.com:27017", #自己是谁
"maxBsonObjectSize" : 16777216,
"maxMessageSizeBytes" : 48000000,
"maxWriteBatchSize" : 1000,
"localTime" : ISODate("2014-10-11T07:00:03.533Z"),
"maxWireVersion" : 2,
"minWireVersion" : 0,
"ok" : 1
}
1.6如果主节点离线,从节点会自动选出主节点
testset:PRIMARY> rs.stepDown() 2014-10-12T17:00:12.869+0800 DBClientCursor::init call() failed 2014-10-12T17:00:12.896+0800 Error: error doing query: failed at src/mongo/shell/query.js:81 2014-10-12T17:00:12.914+0800 trying reconnect to 127.0.0.1:27017 (127.0.0.1) failed 2014-10-12T17:00:12.945+0800 reconnect 127.0.0.1:27017 (127.0.0.1) ok testset:SECONDARY>
可以看到主节点的primary变成了secondary
其他两个节点中的一个变为主节点,这就是自动转移
副本集的重新选举的条件有:心态信息,优先级,optime,网络连接等
1.7还可以修改优先级来实现主从切换
testset:PRIMARY> rs.conf() #查看配置
{
"_id" : "testset",
"version" : 3,
"members" : [
{
"_id" : 0,
"host" : "node2.aolens.com:27017"
},
{
"_id" : 1,
"host" : "node1.aolens.com:27017"
},
{
"_id" : 2,
"host" : "node3.aolens.com:27017"
}
]
}
testset:PRIMARY> cfg=rs.conf() #将配置信息保存在变量中
{
"_id" : "testset",
"version" : 3,
"members" : [
{
"_id" : 0,
"host" : "node2.aolens.com:27017"
},
{
"_id" : 1,
"host" : "node1.aolens.com:27017"
},
{
"_id" : 2,
"host" : "node3.aolens.com:27017"
}
]
}
testset:PRIMARY> cfg.members[1].priority=2 #修改id=1的主机优先级为2
2
testset:PRIMARY> rs.reconfig(cfg) #应用cfg文件
2014-10-12T05:15:59.916-0400 DBClientCursor::init call() failed
2014-10-12T05:15:59.988-0400 trying reconnect to 127.0.0.1:27017 (127.0.0.1) failed
2014-10-12T05:16:00.015-0400 reconnect 127.0.0.1:27017 (127.0.0.1) ok
reconnected to server after rs command (which is normal)
testset:SECONDARY> #主动变为从节点
而id=1的是node1.aolens.com主机,自己变为primary主机
testset:SECONDARY>
testset:PRIMARY>
1.8,如何要设定仲裁节点
rs.addArb(hostportstr)表示将一个节点加进来时就是仲裁节点。
我们移除当前的node3节点
testset:PRIMARY> rs.remove("node3.aolens.com")
删除/mongodb/data下的数据,重新初始化,
testset:PRIMARY> rs.addArb("node3.aolens.com")
二,实现MongoDB数据的的切片
MongoDB的分片(sharding):
为什么要分片:CPU,Memory,IO等无法满足要求。
横行拓展:就需要将数据分片放到不同的节点
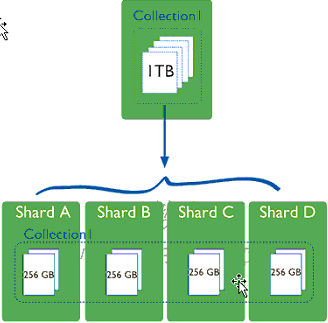
为了保证shard的大小均衡:是将主节点的数据按照顺序分成大小相同的块,分别存在不同的sharding节点上。
分片架构中的角色:
mongos:Router服务器
config server:元数据服务器
shard:数据节点,也成mongod实例
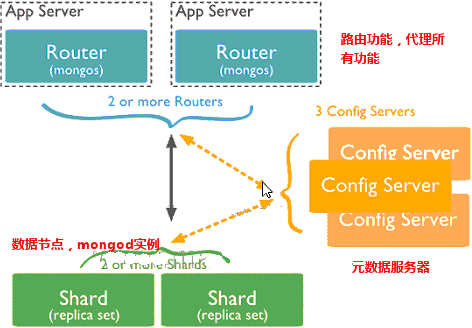
分片需要满足:写离散,读集中的思想
实验环境:
node1:172.16.18.1 mongos router节点
node2:172.16.18.2 mongod shard节点
node3:172.16.18.3 mongod shard节点
node4:172.16.17.12 config server
实验模型:

实验内容:
2.1首先来配置config server
其实config server也就是mongod,只是要指明他就是config server
logpath=/var/log/mongodb/mongod.log logappend=true fork=true #port=27017 dbpath=/mongodb/data pidfilepath=/var/run/mongodb/mongod.pid 启动config server节点。会发现他监听在27019端口 [[email protected] mongodb-2.6.4]# service mongod start Starting mongod: [ OK ] [[email protected] mongodb-2.6.4]# ss -tnl State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 128 *:27019 *:*
2.2配置router节点
安装mongodb-org-mongos.x86_64程序包
直接启动即可:
[[email protected] ~]# mongos --configdb=172.16.17.12:27019 --fork --logpath=/var/log/mongodb/mongos.log 2014-10-11T20:29:43.617+0800 warning: running with 1 config server should be done only for testing purposes and is not recommended for production about to fork child process, waiting until server is ready for connections. forked process: 8766 child process started successfully, parent exiting
启动成功
需要指定config server的地址 --fork后台运行,--logpath指明log位置
2.3配置shard节点,shard节点就是正常的mongod节点,无需什么多的配置
logpath=/var/log/mongodb/mongod.log logappend=true fork=true #port=27017 dbpath=/mongodb/data pidfilepath=/var/run/mongodb/mongod.pid
启动node2,node3
2.4链接在mongos上查看
[[email protected] ~]# mongo --host 172.16.18.1 MongoDB shell version: 2.6.4 connecting to: 172.16.18.1:27017/test
添加两个shard节点: mongos> sh.addShard("172.16.18.2")
{ "shardAdded" : "shard0000", "ok" : 1 }
mongos> sh.addShard("172.16.18.3")
{ "shardAdded" : "shard0001", "ok" : 1 }
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"version" : 4,
"minCompatibleVersion" : 4,
"currentVersion" : 5,
"clusterId" : ObjectId("543922b81aaf92ac0f9334f8")
}
shards:
{ "_id" : "shard0000", "host" : "172.16.18.2:27017" }
{ "_id" : "shard0001", "host" : "172.16.18.3:27017" }
databases:
{ "_id" : "admin", "partitioned" : false, "primary" : "config" }
对数据分片是需要分片的一般为大数据,如果一个collection中的数据很少,就没有必要做shard,而未做分片的数据会放在主shard上。
下来我们先来启动shard功能
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"version" : 4,
"minCompatibleVersion" : 4,
"currentVersion" : 5,
"clusterId" : ObjectId("543922b81aaf92ac0f9334f8")
}
shards:
{ "_id" : "shard0000", "host" : "172.16.18.2:27017" }
{ "_id" : "shard0001", "host" : "172.16.18.3:27017" }
databases:
{ "_id" : "admin", "partitioned" : false, "primary" : "config" }
{ "_id" : "test", "partitioned" : false, "primary" : "shard0000" }
{ "_id" : "testdb", "partitioned" : true, "primary" : "shard0000" }
下来我们手动分片试试
mongos> sh.shardCollection("testdb.students",{"age":1}) #对age来分片
{ "collectionsharded" : "testdb.students", "ok" : 1 }
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"version" : 4,
"minCompatibleVersion" : 4,
"currentVersion" : 5,
"clusterId" : ObjectId("543922b81aaf92ac0f9334f8")
}
shards:
{ "_id" : "shard0000", "host" : "172.16.18.2:27017" }
{ "_id" : "shard0001", "host" : "172.16.18.3:27017" }
databases:
{ "_id" : "admin", "partitioned" : false, "primary" : "config" }
{ "_id" : "test", "partitioned" : false, "primary" : "shard0000" }
{ "_id" : "testdb", "partitioned" : true, "primary" : "shard0000" }
testdb.students
shard key: { "age" : 1 }
chunks:
shard0000 1
{ "age" : { "$minKey" : 1 } } -->> { "age" : { "$maxKey" : 1 } } on : shard0000 Timestamp(1, 0)
可是我们此时没有数据,那么便来生成一些数据吧
mongos> for (i=1;i<=100000;i++) db.students.insert({name:"student"+i,age:(i%100),addr:"china"})
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"version" : 4,
"minCompatibleVersion" : 4,
"currentVersion" : 5,
"clusterId" : ObjectId("543922b81aaf92ac0f9334f8")
}
shards:
{ "_id" : "shard0000", "host" : "172.16.18.2:27017" }
{ "_id" : "shard0001", "host" : "172.16.18.3:27017" }
databases:
{ "_id" : "admin", "partitioned" : false, "primary" : "config" }
{ "_id" : "test", "partitioned" : false, "primary" : "shard0000" }
{ "_id" : "testdb", "partitioned" : true, "primary" : "shard0000" }
testdb.students
shard key: { "age" : 1 }
chunks:
shard0001 1
shard0000 2
{ "age" : { "$minKey" : 1 } } -->> { "age" : 1 } on : shard0001 Timestamp(2, 0)
{ "age" : 1 } -->> { "age" : 99 } on : shard0000 Timestamp(2, 2)
{ "age" : 99 } -->> { "age" : { "$maxKey" : 1 } } on : shard0000 Timestamp(2, 3)
会发现把数据分到了不同的chunk上
数据分片就实现了,当然一般不建议手动分片。
总结:mongod在大数据处理还有主从复制上都有着比MySQL更加优秀的性能和更加简单的操作。但由于mongod尚不是很成熟,在实际的应用中还有许多要解决的问题。需要使用着慢慢摸索。