本文为原创文章,转载请注明出处,谢谢
Master 选举
1、原理
- 服务器争抢创建标志为Master的临时节点
- 服务器监听标志为Master的临时节点,当监测到节点删除事件后展开新的一轮争抢
- 某个服务器成功创建则为Master
2、架构图

- Master:服务器争抢节点
- Servers:服务器列表节点
- work Server:服务器节点
3、流程图
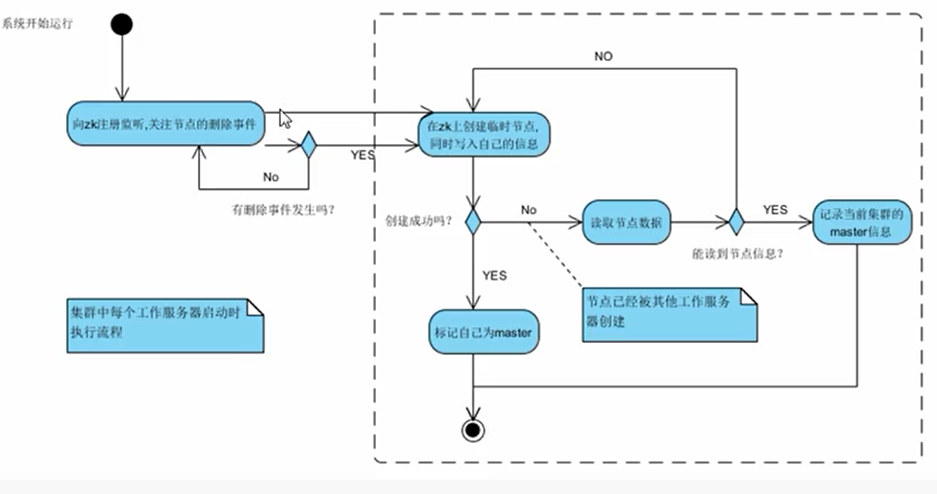
4、核心代码
- workServer监听
public WorkServer(final ServerData serverData) { this.serverData = serverData; dataListener = new IZkDataListener() { @Override public void handleDataChange(String s, Object o) throws Exception { } @Override public void handleDataDeleted(String s) throws Exception { //toBeMaster(); //适应网络抖动 if(null!=masterData && masterData.getName().equals(serverData.getName())) { toBeMaster(); }else{ executorService.schedule(new Runnable() { @Override public void run() { toBeMaster(); } },10, TimeUnit.SECONDS); } } }; }适应网络抖动:当网络发生异常可能会出现短时间的断开,发生此情况时给予节点创建的延时,如果上次保存Master信息为当前节点,则此次Master节点争抢会有10秒钟的优势
- 争抢Master
public void toBeMaster() { if(!running) return; //创建临时节点,session连接失败自动删除 try{ zkClient.create(MASTER_NOTE,serverData, CreateMode.EPHEMERAL); masterData = serverData; System.out.println("当前master:"+masterData.getName()); //测试使用,每5秒释放master节点 if(checkMaster()) { executorService.schedule(new Runnable() { @Override public void run() { releaseMaster(); } },detay,TimeUnit.SECONDS); } }catch (ZkNodeExistsException e){ //如果master节点已经存在 读取 ServerData data = zkClient.readData(MASTER_NOTE,true); //数据为空说明此时master 宕机 if(null==data){ toBeMaster(); }else{ masterData = data; } } }-
ZkNodeExistsException :说明已存在Master节点
- 存在后读取节点数据,如果节点数据不存在则说明此时Master宕机,进行争抢
-
时间: 2024-10-29 19:11:09