拉普拉斯分布的定义与基本性质
其分布函数为
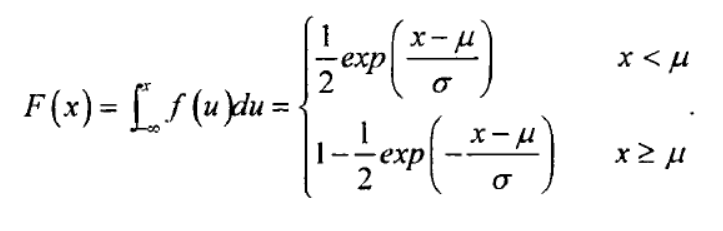
分布函数图
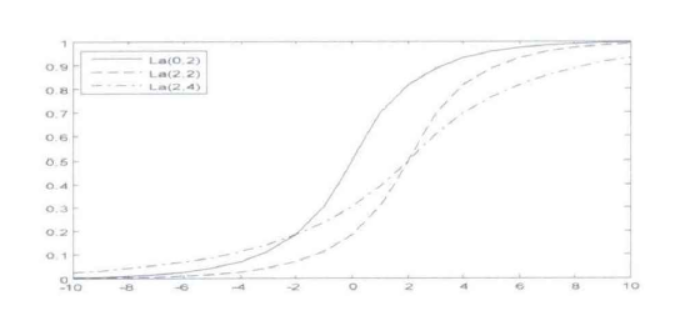
其概率密度函数为
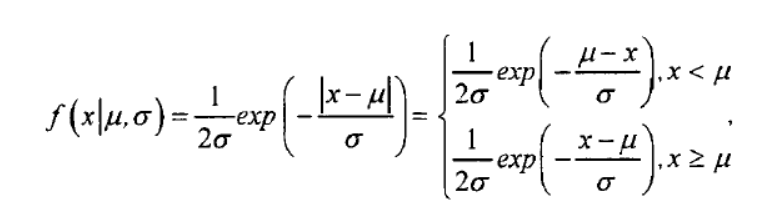
密度函数图
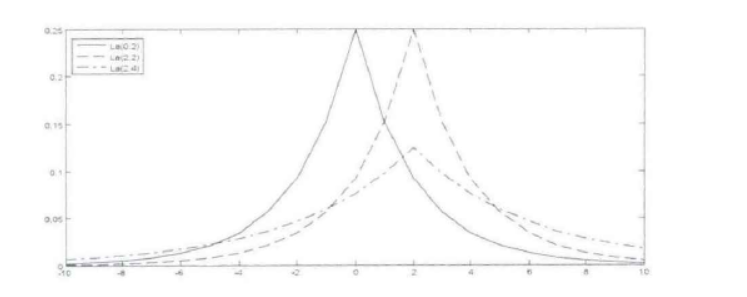
拉普拉斯分布与正太分布的比较
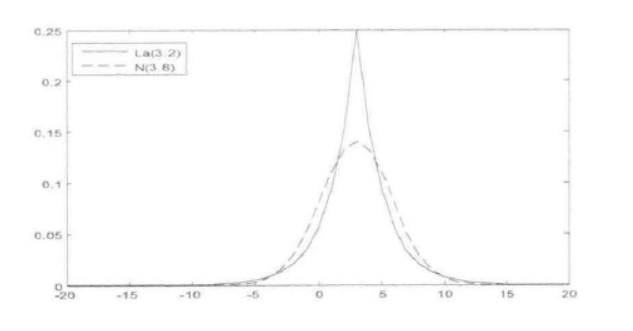
从图中可以直观的发现拉普拉斯分布跟正太分布很相似,但是拉普拉斯分布比正太分布有尖的峰和轻微的厚尾。
原文地址:https://www.cnblogs.com/yifdu25/p/8146446.html
时间: 2024-10-21 04:53:17
其分布函数为
分布函数图
其概率密度函数为
密度函数图
拉普拉斯分布与正太分布的比较
从图中可以直观的发现拉普拉斯分布跟正太分布很相似,但是拉普拉斯分布比正太分布有尖的峰和轻微的厚尾。
原文地址:https://www.cnblogs.com/yifdu25/p/8146446.html