标签(空格分隔): hbase
大数据 (Hadoop)数据库 HBase功能 、表的设计 、环境配置与 Shell基本使用练习,最好与 RDBMS数据中的库和表进行对比 ,以下几点要注意 :
1) 企业中海量数据存储和实时查询的需求
2) HBase功能 ,与 RDBMS相比,优势在哪
3) HBase服务组件的说明、配置部署启动
4) HBase Shell中基本命令的使用
5) HBase 数据存储模型理解,结合实际操作
hadoop,spark,kafka交流群:459898801
1,hbase简介
Hbase是运行在Hadoop上的NoSQL数据库,它是一个分布式的和可扩展的大数据仓库,也就是说HBase能够利用HDFS的分布式处理模
式,并从Hadoop的MapReduce程序模型中获益。这意味着在一组商业硬件上存储许多具有数十亿行和上百万列的大表。除去Hadoop的优
势,HBase本身就是十分强大的数据库,它能够融合key/value存储模式带来实时查询的能力,以及通过MapReduce进行离线处理或者批处理
的能力。
HBase不是一个关系型数据库,它需要不同的方法定义你的数据模型,HBase实际上定义了一个四维数据模型,下面就是每一维度的定义:
行键:每行都有唯一的行键,行键没有数据类型,它内部被认为是一个字节数组。
列簇:数据在行中被组织成列簇,每行有相同的列簇,但是在行之间,相同的列簇不需要有相同的列修饰符。在引擎中,HBase将列簇存储在它自己的数据文件中,所以,它们需要事先被定义,此外,改变列簇并不容易。
列修饰符:列簇定义真实的列,被称之为列修饰符,你可以认为列修饰符就是列本身。
版本:每列都可以有一个可配置的版本数量,你可以通过列修饰符的制定版本获取数据。格式如下:
{row key,column(=<family>+<label>),version}注:
1,rowKey必须具有唯一性
2,数据是没有类型,以字节码的形式存储
3,表:(行key,列簇+列名,版本(timestamp))–>值

可以通过以下两
种方式获得HBase数据:
1,通过他们的行键,或者一系列行键的表扫描。
2,使用map-reduce进行批操作
在HBase中对数据的检索方式
第一种方式:
全部扫描 scan
第二种方式:
依据rowkey进行查询,
第三种方式:
范围查询 scan range
只支持前缀匹配查询
有两个原因令行键的设计十分重要:
表扫描是对行键的操作,所以,行键的设计控制着你能够通过HBase执行的实时/直接获取量。
当在生产环境中运行HBase时,它在HDFS上部运行,数据基于行键通过HDFS,如果你所有的行键都是以user-开头,那么很有可能你大部分数据都被分配一个节点上(违背了分布式数据的初衷),因此,你的行键应该是有足够的差异性以便分布式地通过整个部署。
你定义行键的方式取决于你想怎样存取那些行。如果你想以用户为基础存储数据,那么一个策略是利用字节队列在HBase中存储行键,所以我们可以创建
一个用户ID的哈希(例如MD5或SHA-1),然后在哈希后面附上时间(long类型)。使用哈希有两个重点:(1)是它能够将value分散开,数据
能够分布式地通过簇,(2)是它确保key的长度是一致的,以更加容易在表扫描中使用。
2,hbase VS RDMS
HBase和关系数据库的比较
HBase是一个基于列模式的映射数据库,它只能表示很简单的键-数据的映射关系,这大大简化了传统的关系数据库。与关系数据库相比,它有如下特点:
1,数据类型
HBase只有简单的字符串类型,所有的类型都是交由用户自己处理的,它只保存字符串。
而关系数据库有丰富的类型选择和存储方式。
2,数据操作
HBase只有很简单的插入、查询、删除、清空等操作,表和表之间是分离的,没有复杂的表和表之间的关系,所以不能、也没有必要实现表和表之间的关联等操作。
而传统的关系数据通常有各种各样的函数、连接操作。
3,存储模式
HBase是基于列存储的,每个列族都由几个文件保存,不同列族的文件是分离的。
传统的关系数据库是基于表格结构和行模式保护的。
4,数据维护
确切的说,HBase的更新操作不应该叫做更新,虽然一个主键或列对应新的版本,但它的旧版本仍然会保留,所以它实际上是插入了新的数据,而不是传统关系数据库里面的替换修改。
5,可伸缩性
HBase这类分布式数据库就是为了这个目的而开发出来的,所以它能够轻松地增加或减少(在硬件错误的时候)硬件数量,并且对错误的兼容性比较高。
而传统的关系数据库通常需要增加中间层才能实现类似的功能。
3,hbase部署
3.1 安装Zookeeper
- 安装JDK、配置环境变量、验证java -version。
- 下载、赋执行权限、解压。
(1).下载地址:
(2).赋执行权限:
{kind=link}
chmod u+x zookeeper-3.4.5.tar.gz(3).解压:
tar -zxvf zookeeper-3.4.5.tar.gz -C /opt/modules/- 配置
复制配置文件:
cp conf/zoo_sample.cfg conf/zoo.cfg配置数据存储目录:
dataDir=/opt/modules/zookeeper-3.4.5/data创建数据存储目录:
mkdir /opt/modules/zookpeer-3.4.5/data- 启动
bin/zkServer.sh start- 检测
查看状态:bin/zkServer.sh statusClient Shell:bin/zkCli.sh3.2 安装hbase
1,解压hbase
tar -zxvf /opt/softwares/hbase-0.98.6-hadoop2-bin.tar.gz -C /opt/modules/2,删除自带的hadoop库
rm -rf hadoop-*.jar3,在hbase-env.sh更改如下内容
export JAVA_HOME=/opt/modules/jdk1.7.0_67
export HBASE_MANAGES_ZK=false4,regionservers.中添加如下内容
adddeiMac.local5,在hbse-site.xml中添加如下配置
<property>
<name>hbase.tmp.dir</name>
<value>/opt/modules/hbase-1.0.0-cdh5.4.4/data/tmp</value>
</property>
<property >
<name>hbase.rootdir</name>
<value>hdfs://adddeiMac.local:8020/hbase</value>
</property>
<property >
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>adddeiMac.local</value>
</property>6,启动hbase
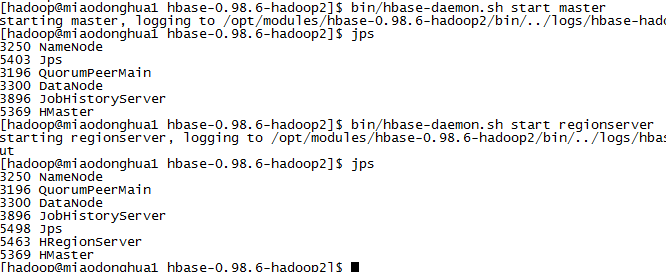
bin/hbase-daemon.sh start master
bin/hbase-daemon.sh start regionserver
7,可在web浏览器中查看
http://miaodonghua1.host:60010/
8,在Zookeeper中查看hbase信息

9,解决不能删除的问题
在secureCRT中,点击【选项】【会话选项】【终端】【仿真】,右边的终端选择Linux,在hbase shell中如输入出错,按住SHIT+DELETE 即可删除!
10,启动hbase命令行控制台
bin/hbase shell11,测试hbase指令
查看状态及版本信息
status
version
创建表并插入数据
create ‘user‘,‘info‘
list ---列出表
describe ‘user‘---查看表信息
create ‘user‘,‘info‘
put ‘user‘,‘1001‘,‘info:name‘,‘lisi‘
put ‘user‘,‘1001‘,‘info:age‘,‘18‘
put ‘user‘,‘1001‘,‘info:sex‘,‘male‘
对表进行扫描查询
scan ‘user‘
获取表的某一个rowkey所有信息
get ‘user‘,‘1001‘
获取表的某一列
get ‘user‘,‘1001‘,‘info:name‘
删除表的一列
delete ‘user‘,‘10012‘,‘info:sex‘
禁止表
disable ‘user‘
使能表
enable ‘user‘
删除表先禁用
4,hbase存储模型
1,Table中所有行都按照row key的字典序排列;
2,Table在行的方向上分割为多个Region;

下图是大表的分布式,永久分区逻辑存储结构图

3,REgion按大小分割,每个表开始只有一个region,随着数据增多,region不断增大,当增大到一个阀值的时候region就会分为两个新的region,之后会有越来越多的region;

4,Region是HBase中分布式存储和负载均衡的最小单元。不同Region分布到不同RegionServer上;

5,Region虽然是分布式存储的最小单元,但并不是存储的最小单元。
-Region由一个或者多个store组成,每个store保存一个columns family;
-每个Store又有一个memStore和0至多个StoreFile组成;
-memStore存储在内存中,StoreFile存储在HDFS上。

-每个column family存储在HDFS上的一个单独文件中;
-Key和Version number在每个column family中均有一份
-空值不会被保存
-Hbase为每个值维护了多级索引,即:
5,hbase在hdfs上各目录的意义

/hbase/.tmp
/hbase/WALs
/hbase/archive
/hbase/corrupt
/hbase/data
/hbase/hbase.id
/hbase/hbase.version
/hbase/oldWALs1、/hbase/.tmp
这个目录不变还是原来的tmp目录,作用是一样的。
2、/hbase/WALs
日志存储目录
3、/hbase/archive
HBase 在做 Split或者 compact 操作完成之后,会将 HFile 移到.archive 目录中,然后将之前的 hfile 删除掉,该目录由 HMaster 上的一个定时任务定期去清理。
4、/hbase/corrupt
存储HBase做损坏的日志文件,一般都是为空的。
5、/hbase/data
这个才是 hbase 的核心目录,0.98版本里支持 namespace 的概念模型,系统会预置两个 namespace 即:hbase和default
5.1 /hbase/data/default
这个默认的namespace即没有指定namespace 的表都将会flush 到该目录下面。
5.2 /hbase/data/hbase
这个namespace 下面存储了 HBase 的 namespace、meta 和acl 三个表,这里的 meta 表跟0.94版本的.META.是一样的,自0.96之后就已经将 ROOT 表去掉了,直接从Zookeeper 中找到meta 表的位置,然后通过 meta 表定位到 region。 namespace 中存储了 HBase 中的所有 namespace 信息,包括预置的hbase 和 default。acl 则是表的用户权限控制。
如果自定义一些 namespace 的话,就会再/hbase/data 目录下新建一个 namespace 文件夹,该 namespace 下的表都将 flush 到该目录下。
6、/hbase/hbase.id
它是一个文件,存储集群唯一的 cluster id 号,是一个 uuid。
7、/hbase/hbase.version
同样也是一个文件,存储集群的版本号,貌似是加密的,看不到,只能通过web-ui 才能正确显示出来。
8、/hbase/oldWALs
当WALs 文件夹中的 HLog 没用之后会 move 到oldWALs中,HMaster 会定期去清理。