今天给大家介绍的内容主要包括以下四个部分首先是介绍一下美团大数据平台的架构,然后回顾一下历史,看整个平台演进的时间演进线,每一步是怎么做的,以及一些挑战和应对策略,最后总结一下,聊一聊我对平台化的看法。
谢语宸是来自美团的大数据构建平台的架构师。他在QCon2016北京站分享了一些整体上构建大数据平台的方法,除了聚焦在某一个点上的还有构建整体的大数据,以及各种各样技术的应用,希望能给大家一些关于大数据方面的启迪。

非常感谢给我这个机会给大家带来这个演讲,我是2011年加入美团,最开始负责统计报表还有数据仓库的建设。2012年推动了数据仓库分布式化,把分布式计算放到了Hadoop上,之后把数据开发流程放到了线上,2014年带离线平台团队。
我今天给大家介绍的内容主要包括以下四个部分首先是介绍一下美团大数据平台的架构,然后回顾一下历史,看整个平台演进的时间演进线,每一步是怎么做的,以及一些挑战和应对策略,最后总结一下,聊一聊我对平台化的看法。
1.美团大数据平台的架构
1.1总体架构:
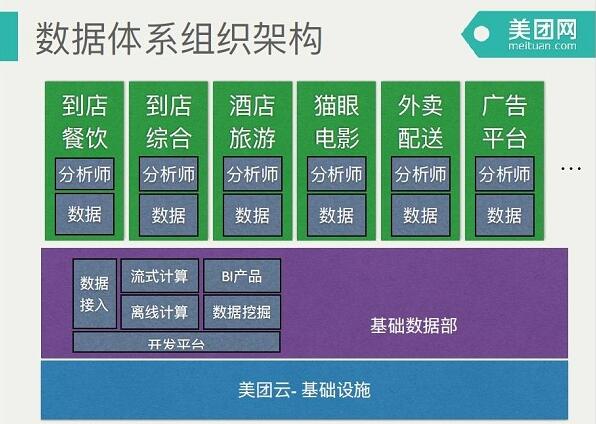
上图是美团网数据体系组织架构图,上面每一个竖线都是数据开发业务线,下面是我所在的基础数据库团队, 最下面我们依赖美团云提供的一些虚拟机、物理机、机房等基础设施,同时我们也协助美团云做了大数据云服务的产品探索。
1.2数据流架构:
下面我以数据流的架构角度介绍一下整个美团数据平台的架构,这是最恢复的架构图,最左边首先从业务流到平台,分别到实时计算,离线数据。

最下面支撑这一系列的有一个数据开发的平台,这张图比较细,这是我们详细的整体数据流架构图。包括最左边是数据接入,上面是流式计算,然后是Hadoop离线计算。
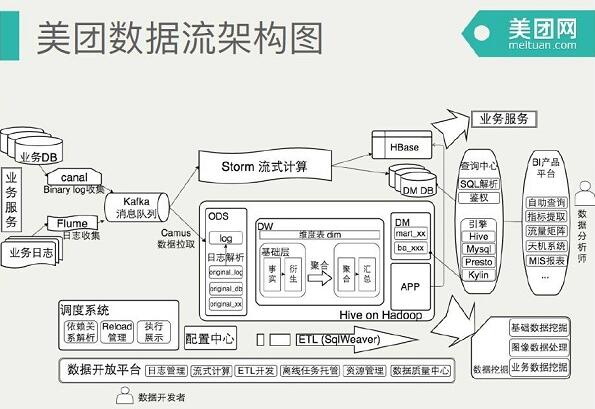
将上图左上角扩大来看,首先是数据接入与流式计算,电商系统产生数据分两个场景,一个是追加型的日志型数据,另外是关系型数据的维度数据。我们对于前一种是使用Flume比较标准化的,大家都在用的日志收集系统。最近使用了阿里开源的Canal,之后有三个下游。所有的流式数据都是走Kafka这套流走的。
数据收集特性:
对于数据收集平台,日志数据是多接口的,可以打到文件里观察文件,也可以更新数据库表。关系型数据库是基于Binlog获取增量的,如果做数据仓库的话有大量的关系型数据库,有一些变更没法发现等等的情况,通过Binlog手段可以解决。通过一个Kafka消息队列集中化分发支持下游,目前支持了850以上的日志类型,峰值每秒有百万介入。
流式计算平台特性:
构建流式计算平台的时候充分考虑了开发的复杂度,基于Storm。有一个在线的开发平台,测试开发过程都在在线平台上做,提供一个相当于对Storm应用场景的封装,有一个拓扑开发框架,因为是流式计算,我们也做了延迟统计和报警,现在支持了1100以上的实时拓扑,秒级实时数据流延迟。
这上面可以配置公司内部定的某个参数,某个代码,可以在平台上编译有调试。实时计算和数据接入部分就介绍到这儿,下面介绍一下离线计算。
离线计算:我们是基于Hadoop的数据仓库数据应用,主要是展示了对数据仓库分成的规划,包括原始数据接入,到核心数据仓库的基础层,包括事实和衍生事实,维度表横跨了聚合的结果,最右边提供了数据应用:一些挖掘和使用场景,上面是各个业务线自建的需求报表和分析库。
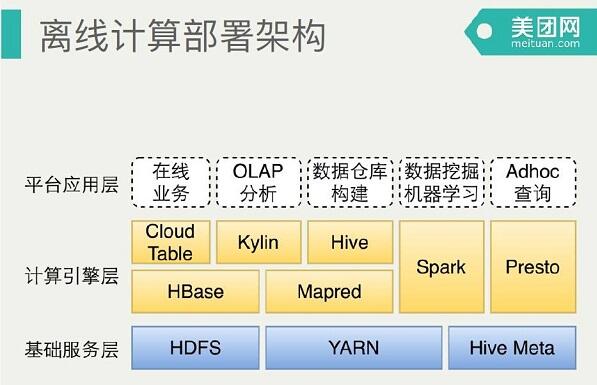
这幅图是离线数据平台的部署架构图,最下面是三个基础服务,包括Yarn、HDFS、HiveMeta。不同的计算场景提供不同的计算引擎支持。如果是新建的公司,其实这里是有一些架构选型的。Cloud Table是自己做的HBase分装封口。我们使用Hive构建数据仓库,用Spark在数据挖掘和机器学习,Presto支持Adhoc上查询,也可能写一些复杂的SQL。对应关系这里Presto没有部署到Yarn,跟Yarn是同步的,Spark 是 on Yarn跑。目前Hive还是依赖Mapreduce的,目前尝试着Hive on tez的测试和部署上线。
离线计算平台特性:
目前42P+总存储量,每天有15万个Mapreduce和Spark任务,有2500万节点,支持3机房部署,后面跨机房一会儿会介绍,数据库总共16K个数据表,复杂度还是蛮高的。
1.3数据管理体系:
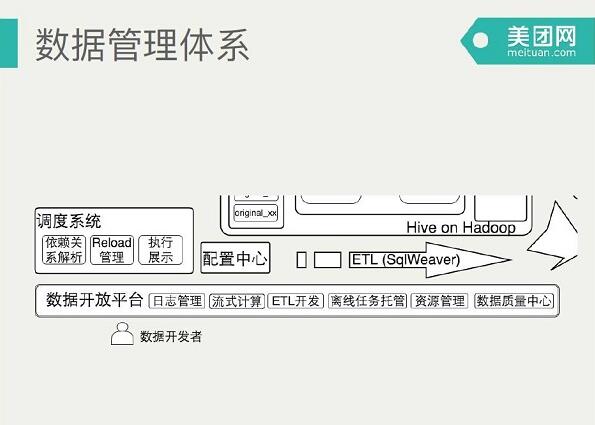
数据管理体系特性:
下面简单聊一下数据管理体系,这相当于主要面向数据开发者的操作经验,主要包括自研的调配系统,然后数据质量的监控,资源管理和任务审核一条开发配置中心等等,都是在数据管理体系的,下面会整合到整个的数据开放平台。
数据管理体系我们这边主要实现了几点,
第一点我们是基于SQL解析去做了ETL任务之间的自动解析。
基于资源预留的模式做了各业务线成本的核算,整体的资源大体是跑到Yarn上的,每个业务线会有一些承诺资源、保证资源,还可以弹性伸缩,里面会有一些预算。
我们工作的重点,对于关键性任务会注册SLA保障,并且包括数据内容质量,数据时效性内容都有一定的监控。
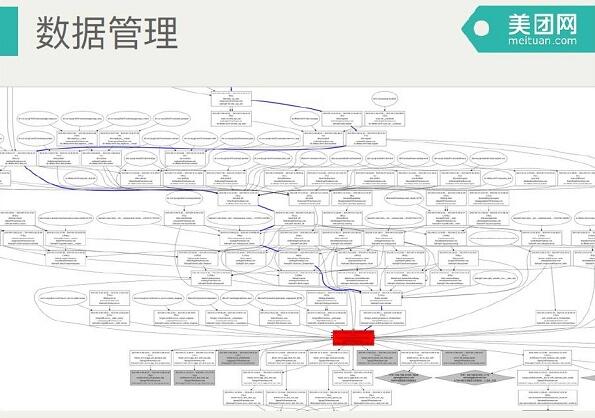
这是解析出来的依赖关系,红色的是展示的一条任务,有一系列的上游。这是我们的资源管理系统,可以分析细到每个任务每时每刻的资源使用,可以聚合,给每个业务线做成本核算。
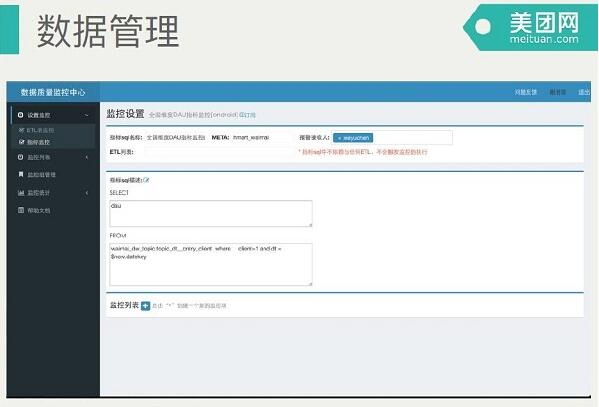
这是对于数据质量管理中心,图比较小,上面可以写一些简单的SQL,监控某一个表的数据结果是否符合我们业务的预期。下面是数据管理,就是我们刚刚提到的,对每个关键的数据表都有一些SLA的跟踪保障,会定期发日报,观察他们完成时间的一些变动。
1.4BI产品:
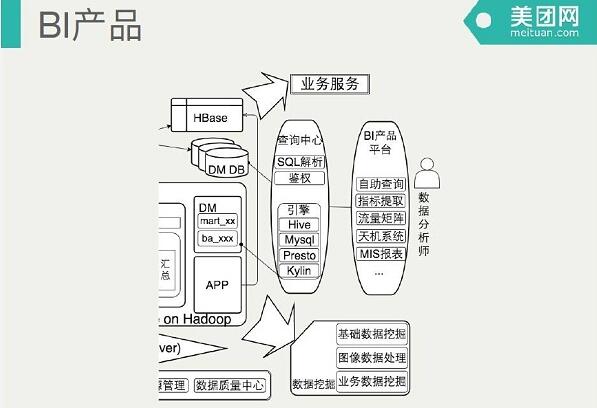
上面是BI产品,数据应用平台化的场景。我们的查询主要是有一个查询中心来支持,包括Hive,MySQL,Presto,Kylin等等的引擎,在查询中心里面我们做SQL解析。前面是一系列的BI产品,大部分是自研的,面向用户可以直接写SQL的自主查询,并且看某一个指标,某一个时间段类似于online的分析数据产品,以及给老大们看的天机系统。
还有指标提取工具,其实跟商用oneline前端分析引擎设计是比较类似的,选取维度范围,还有适时的计算口径,会有一系列对维度适时的管理。数据内容数据表不够,还会配一些dashboard。
我们开发了星空展示中心,可以基于前面指标提取结果,配置一系列的饼图、线图、柱状图,去拖拽,最后build出来一个dashboard。
2.平台演进时间线
2.1 平台发展

下面聊一下整个数据平台发展的时间线。因为我是2011年加入美团的,美团刚刚建立一年左右。最开始2011年的时候,我们主要的数据统计都是基于手写的报表,就是来一个需求我们基于线上数据建立一个报表页面,写一些表格。这里带来的严重的问题,首先是内部信息系统的工作状态,并不是一个垂直的,专门用做数据分析的平台。这个系统当时还是跟业务去共享的,跟业务的隔离非常弱,跟业务是强耦合的,而且每次来数据需求的时候我们都要有一些特殊的开发,开发周期非常长。
我们面对这个场景怎么办呢?我们做了一个目前来看还算比较好的决策,就是重度依赖SQL。我们对SQL分装了一些报表工具,对SQL做了etl工具。主要是在SQL层面做一些模板化的工具,支持时间等变量。这个变量会有一些外部的参数传递进来,然后替换到SQL的行为。
我们在2011下半年引入了整个数据仓库的概念,梳理了所有数据流,设计整个数据体系。做完了数据仓库整体的构建,我们发现有整体的ETL被开发出来了。首先ETL都是有一定的依赖关系的,但是管理起来成本非常高。所以我们自研了一个系统,另外我们发现数据量越来越大,原来基于单机MySQL的数据解析是搞不定的,所以2012年我们上了四台Hadoop机器,后面十几台,到最后的几千台,目前可以支撑各个业务去使用。
2.2 最新进展
我们也做了一个非常重要的事就是ETL开发平台,原来都是基于Git仓库管理,管理成本非常高,当时跟个业务线已经开始建立自己数据开发的团队了。我们把他们开发的整个流程平台化,各个业务线就可以自建。之后我们遇到的业务场景需求越来越多,特别是实时应用。2014年启动了实时计算平台,把原来原有关系型数据表全量同步模式,改为Binlog同步模式。我们也是在国内比较早的上了Hadoop2.0 on Yarn的改进版,好处是更好的激起了Spark的发展。另外还有Hadoop集群跨多机房,多集群部署的情况,还有OLAP保障,同步开发工具。
3.近期挑战和应对
3.1Hadoop多机房
Hadoop多机房背景:
下面重点讲三个挑战还有应对策略,首先是Hadoop多机房。Hadoop为什么要多机房部署呢?之前只有淘宝这样做。2015年初我们被告知总机房架位只有500个节点,我们迁到的机房,主要还是机房合同发生了一些违约。我们沟通到新的离线机房需要在9月份交付,2015年6月份我们需要1000个计算节点,12月份的时候需要1500个计算节点,这肯定是不够的。那就要进行梳理,业务紧耦合,快速拆分没法支撑快速增长,而且数据仓库拆分会带来数据拷贝,数据传输成本的,这时候只能让Hadoop多机房进行部署。
我们思考了一下,为什么Hadoop不能多机房部署呢?
其实就两个问题。
一个是跨机房带宽非常小,而且跨机房带宽比较高,几十G,可能给力的能上百G,但是机房核心交换节点是超过这些的。而且Hadoop是天生的分布式系统,他一旦跨节点就一定会有跨机房的问题。
我们梳理了Hadoop运行过程中,跨节点的数据流程,基本上是三种。
首先是APP内部,就是任务内部的一些Container通信的网络交换,比较明确的场景就是Map和educe之间。
第二个是非DataNode本地读取,如果跨机房部署读数据就是跨机房的,带宽量非常大。
第三个写入数据的时候要构建一个三节点的pipeline,可能是跨机房的,就要带来很多数据流量。
Hadoop多机房架构决策:
我们当时考虑到压力,先做多机房的方案再做NameSpace,这跟淘宝方案有所差别。我们每个节点都有一个所属的机房属性,把这个东西维护起来,基本上也是基于网络段判断的。对于刚刚提到的第一个问题,我们的方案在Yarn队列上打一个机房的tag,每个队列里面的任务只会在某一个机房里跑起来,这里要修改一下Yarn fairscheduler的代码的。
第二个是基于HDFS修改了addBlock策略,只返回client所在机房的DataNode列表,这样写入的时候pipeline就不会有跨机房,读取也会优先选取clinet所在的机房。还有其他的场景会跨机房,比如说Balancer也是节点之间做数据迁移的。最终我们还做了一件事,就是Balancer是直接DataNode沟通,有通道的,我们是直接构造了Block文件分布工具。
Hadoop多机房结构效果:
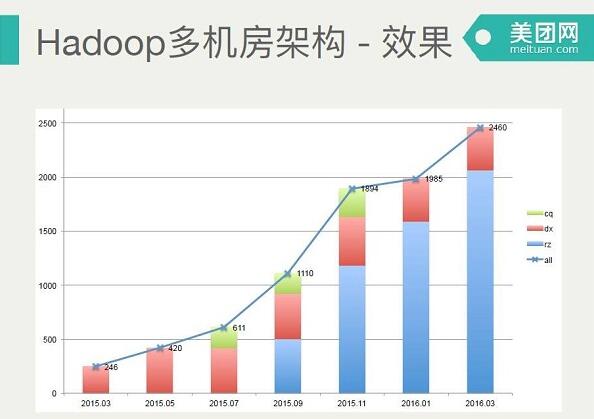
效果上看,左边是2015年3月份节点数,300多,2016年3月份是2400多,中间不同的段是每个机房当时承载的节点数。这时候我们只有一个机房了,因为我们整个跨机房,多机房的方案是为了配合一个临时的状态,所以它方案前面通过Balancer模块的接口,把所有数据最终都搬迁到了大的离线计算机房。
Hadoop多机房架构特点:
做这个架构的时候,我们设计的时候主要考虑第一代码改动要小,因为当时我们团队没有那么深的对Hadoop代码的掌控,我们要保证设计出来的结果,对于Hadoop原生逻辑的影响范围是可控的;第二个是能快速开发,优先顶住节点资源分布不够的问题;第三个整个迁移过程是业务全透明的,只要在他数据读取之前把块分布到我希望任务所调动的机房就可以了。
3.2 任务托管和交互式开发
任务托管和交互式开发背景:
我们原来的方式是给业务线去布一些开源原生Hadoop和Spark的Client的。
在本机要编写代码和编译,拷到线上的执行节点,因为要有线上的认证。
并且要部署一个新的执行节点的时候,要给我们提申请,分配虚拟机,key和client,这个管理成本非常高。
而且同一个团队共享一个虚拟机开发总会遇到一个问题,某个虚拟机会被内存任务占满,要解决这个问题。
而且由于在Spark发展的过程中,我们会持续地给业务提供Spark技术支持这样一个服务。如果大家写代码运行失败了,他们没有那么强的debug能力,当我们上手帮他们debug的时候,首先编译环境、执行环境,编译代码内容我们都没法第一时间获取,这个沟通成本是非常高的。同时在推Spark的时候,我们发现它的开发效率非常高,学习尝试的成本也是非常高的。那怎么办呢?
任务托管和交互式开发架构决策:
为了解决学习成本高的问题,我们做了两个事。
一个是任务托管平台,将任务的代码编译打包、执行、测试还有最终上线跑,都统一在一个平台进行管理。
另一个是我们推动了交互式开发工具,当时调研了ipthon notebook + spark和zeppelin,最后选择了zeppelin,觉得比较成熟。基于后者开发,修复了一系列bug,补充登陆认证。效果是任务托管平台,本机编写代码,提交代码到公司公有的地址上。在这个平台界面,平台界面进来都不是必须的了,还进行了本机的任务行,提交一个任务,开始在平台上统一测试,统一执行,最后还可以基于这个配置到我们刚刚说到的自研调度系统。
交互式开发目前可能都需要二次开发才能做起来,但是值得尝试。业务线用它的话主要是两个场景,第一个场景是要分析、调研一些数据。原来我们提供adhoc的Sql的查询接口其实并不一定能满足他的需求,他要查查接口有一些sql查询复杂数据,如果想用spark每次用spark都要编译或者用Spark管理起来非常不直观。
另外有一些先行Spark尝试者写了一些Spark的应用,这些应用如何让其他同学也能看到,也能对他进行学习和理解,并且能支持他自己构建自己的应用场景呢?也可以通过这么一个平台化的代码、结果,对应展示的平台来解决他们交互的问题。
3.3 OLAP引擎
OLAP引擎的需求特点:
最后聊一下在OLAP引擎部分的探索,大概2015年末的时候,我们开始关注到业务的数据集市,数据量已经非常大了,而且包括维度,表的大小、复杂度都增长的非常快。这些业务也比较崩溃,MySQL和HBase都会做一些特殊的方法来支持。我们调研了一下需求,普遍说是要支持亿级别的事实,指标的话每个cube数据 立方体要有50个以内,要支持取值范围在千万级别维度20个以内类别;
查询请求,因为数据集市一般都是提供给销售管理团队去看业绩,对延迟要求比较高,对我们当时TP99,前99%查询要小于3秒钟。
有多种维度组合聚合查询,因为要上转下转对业务进行分析。
还有一个特点,就是对去重的指标要求比较精确,因为有些涉及到业绩的指标比如团购单,去重访问用户数如果有偏差会影响到业绩的预算。
OLAP引擎可能的方案:
当时考虑到了业界可能的方案,
一个是原来推荐的使用方法,就是Presto、hive、Spark on ORCFile,这是最早的方案。
另外有先行的业务方案,基于hive grouping set的功能,把grouping set按不同维度组合去做聚合,然后形成一个大表,导到HBase里,HBase按需做二级索引的方案,这其实还是有一些瓶颈的。
还有社区里兴起的Druid、Elasticsearch还有Kylin这些项目,我们面临这样的场景思路是这样的。首先直观的看,考虑稳定性、成熟度,以及团队对这个产品可能的掌控程度,还有社区的活跃度,我们优先尝试Kylin。我们团队有两个Kylin contributors。
OLAP引擎探索思路:
由于前面有这样多的解决方案,我们怎么保证我们选的解决方案是靠谱的呢?我们基于dpch构建了一个Star Schema Benchmark构造了OLAP场景和测试数据;我们用这一套数据结构和数据内容对不同的引擎进行测试,看它的表现和功能性,满足的情况。并且推动的过程中持续的分享我们调研和压缩的进展,优先收集他们实际业务场景需求之后,再回过头来改进数据集市的需求,更适合业务线需求,下图就是Kylin的界面。
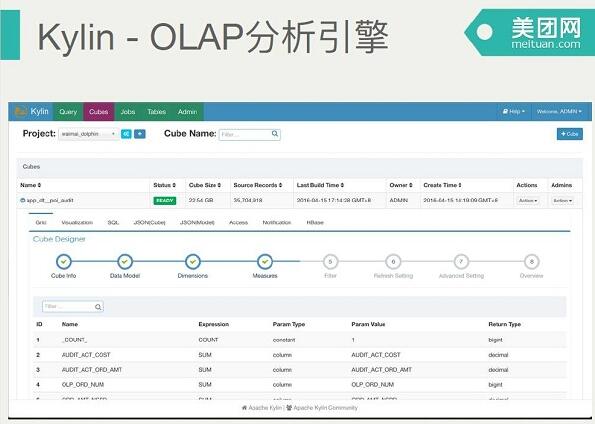
具体它提供一个界面声明你的维度、事实,有哪些指标,这些指标会被怎样聚合,会生成Mapreduce任务,出来的结果会按照设计进行压缩,导到HBase里面。他还提供一个SQL引擎,会转成HBase上查询,把结果捞出来,总体来讲还是蛮成熟的。

这是StarSchemaBenchmark,一张大的事实表,有很多维度挂在上面,我们做了很多不同数据量级的参照,也参照了现实的数据。
OLAP引擎目前进展:
目前进展的话,我们完成了Presto、Kylin1.3、Kylin1.5,Druid测试。这个确实比Kylin好一些,但是有特殊场景,天生不支持SQL接口,所以不会重度使用。
我们拿Kylin支持了某个BI项目7个数据立方体,数据立方体基本上是一个事实,带一系列维度,是某一个场景下的分析。
业务开发周期做一系列的聚合表,梳理聚合成绩,维护这些聚合成绩7天缩短到一天。
线上实际跑的数据有3亿行数据,TP95%查询响应时间在1S内,TP99是3秒内;支撑外卖团队日查询量2万。由于这是外卖的销售团队去看,他们量非常大。
4.平台化思路总结
4.1平台的价值:
最后聊一下做了这么多年数据平台,对于数据平台的思考。我觉得平台不管是不是数据平台,作为一个平台的团队,核心价值其实就是这三个。
第一个是对重复的事情,这一个平台团队做精做专,而且重复的事情只做一次,减少投入。
另外统一化,可以推一些标准,推一些数据管理的模式,减少业务之间的对接成本,这是平台的一大价值。
最重要的是为业务整体效率负责,包括开发效率、迭代效率、维护运维数据流程的效率,还有整个资源利用的效率,这都是要让业务团队对业务团队负责的。无论我们推什么事情,第一时间其实站在业务的角度要考虑他们的业务成本。
4.2平台的发展:
如果才能发展成一个好的平台呢?
我理解是这三点:
首先支持业务是第一位的,如果没有业务我们平台其实是没法继续发展的。
第二是与先进业务同行,辅助并沉淀技术。在一个所谓平台化的公司,有多个业务线,甚至各个业务线已经是独立的情况下,必定有一些业务线是先行者,他们有很强的开发能力、调研能力,我们的目标是跟这些先行业务线同行。我们跟他们一起走的过程中,一方面是辅助他们,能解决一系列的问题。比如说他们有突发的业务需求,遇到问题我们来帮助解决。
第三是设立规范,用积累的技术支撑后发业务。就是跟他们一起前进的过程中,把一些经验、技术、方案、规范慢慢沉淀下来。对于刚刚新建的业务线,或者发展比较慢的业务线,我们基本策略是设置一系列的规范,跟优先先行业务线积累去支撑后续的业务线,以及功能开发的时候也可以借助。保持平台团队对业务的理解。
4.3关于开源:
最后聊一下开源,刚刚也提到了我们同时对开源有一些自己需求的改进和重构,但是同时又一些产品是我们直接开源的来用的,比如说,zeppelin,Kylin。
我们的策略是持续关注,其实也是帮业务线做前瞻性调研,他们团队每天都在看数据,看新闻,他们会讲新出的一个项目你们怎么推,你们不推我们推了,我们可能需要持续关注,设计一系列的调研方案,帮助这些业务去调研,这样调研这个事情我们也是重复的事情只干一次。
如果有一些共性patch的事情,特别一些bug、问题内部也会有一个表共享,内部有大几十个patch。选择性的重构,最后才会大改,特别在选择的时候我们起来强调从业务需求出发,理智的进行选型权衡,最终拿出来的方案是靠谱能落地实施的方案,我的分享就到这里,谢谢大家。