一、获取你想要抓取的网站地址:
然后打开控制台,F12,打开。我用的是Chrome浏览器,跟个人更喜欢Chrome的控制台字体。
找到搜索栏对应的html标签:


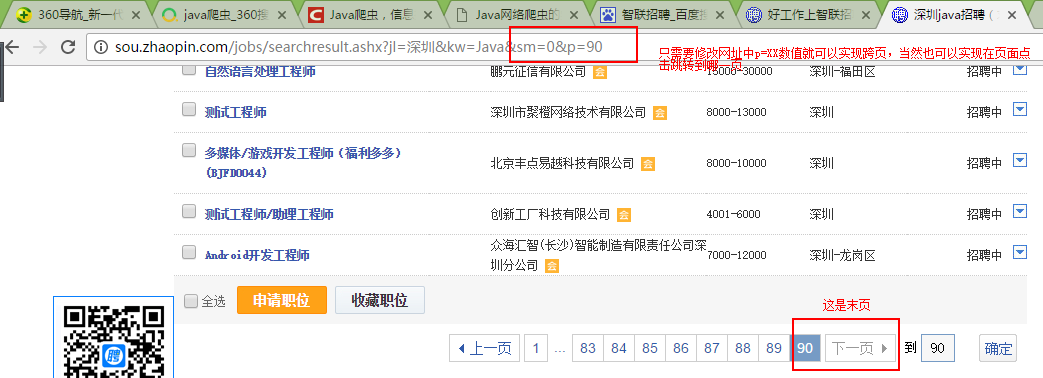
http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%E6%B7%B1%E5%9C%B3&kw=Java&sm=0&p=1
也可以直接在地址栏输入这个网址。和之前在输入职位框输入java,地区为深圳是一致的,在之前点击“搜工作”按钮也是这样跳转到这个页面的。
下面这一栏是搜索的结果条数,可能对于我们执行循环有帮助。

这是定位到某个页面的所有招聘信息的html的div块:

那么具体到某一家公司的招聘信息:

这就对应到这一家公司了:
 但是我们需要的是具体的信息,于是我们展开刚才上面那个<table></table>的<tr></tr>:
但是我们需要的是具体的信息,于是我们展开刚才上面那个<table></table>的<tr></tr>:
所有的标签展开内容过长,我们分开来看:

 那么还有一个我们在网页上看见的:下拉箭头。打开下拉箭头就会看到详细信息,这里其实该页面的html已经包含了,只是默认隐藏而已。
那么还有一个我们在网页上看见的:下拉箭头。打开下拉箭头就会看到详细信息,这里其实该页面的html已经包含了,只是默认隐藏而已。
 对应的显示结果:
对应的显示结果:
 那么我想获取的是什么信息呢,我不会获取太多信息。这里我只想获取的是“岗位名称”、“经验”、“学历”、“薪水”等。如果需要获取岗位要求和公司地址的话,则必须点击进入该岗位下进行查看。
那么我想获取的是什么信息呢,我不会获取太多信息。这里我只想获取的是“岗位名称”、“经验”、“学历”、“薪水”等。如果需要获取岗位要求和公司地址的话,则必须点击进入该岗位下进行查看。


时间: 2024-08-29 10:25:29