线索二叉树它解决了无法直接找到该结点在某种遍历序列中的前趋和后继结点的问题,出现了二叉链表找左、右孩子困难的问题,线索二叉树又分为前序线索化,中序线索化和后序线索化,分别用不同的逻辑去实现。
线索二叉树的实现思想:借用一个枚举类型tag其中包含两个状态Link(代表有数据),thread(代表下一个节点为空)在一个节点的左节点或者右节点为空的情况下,将它的left或right设为thread,则它的左或右访问的是改遍历模式下访问到的下一个节点数据,这样就完成了跳到另一颗子树的过程,减少了递归的次数。
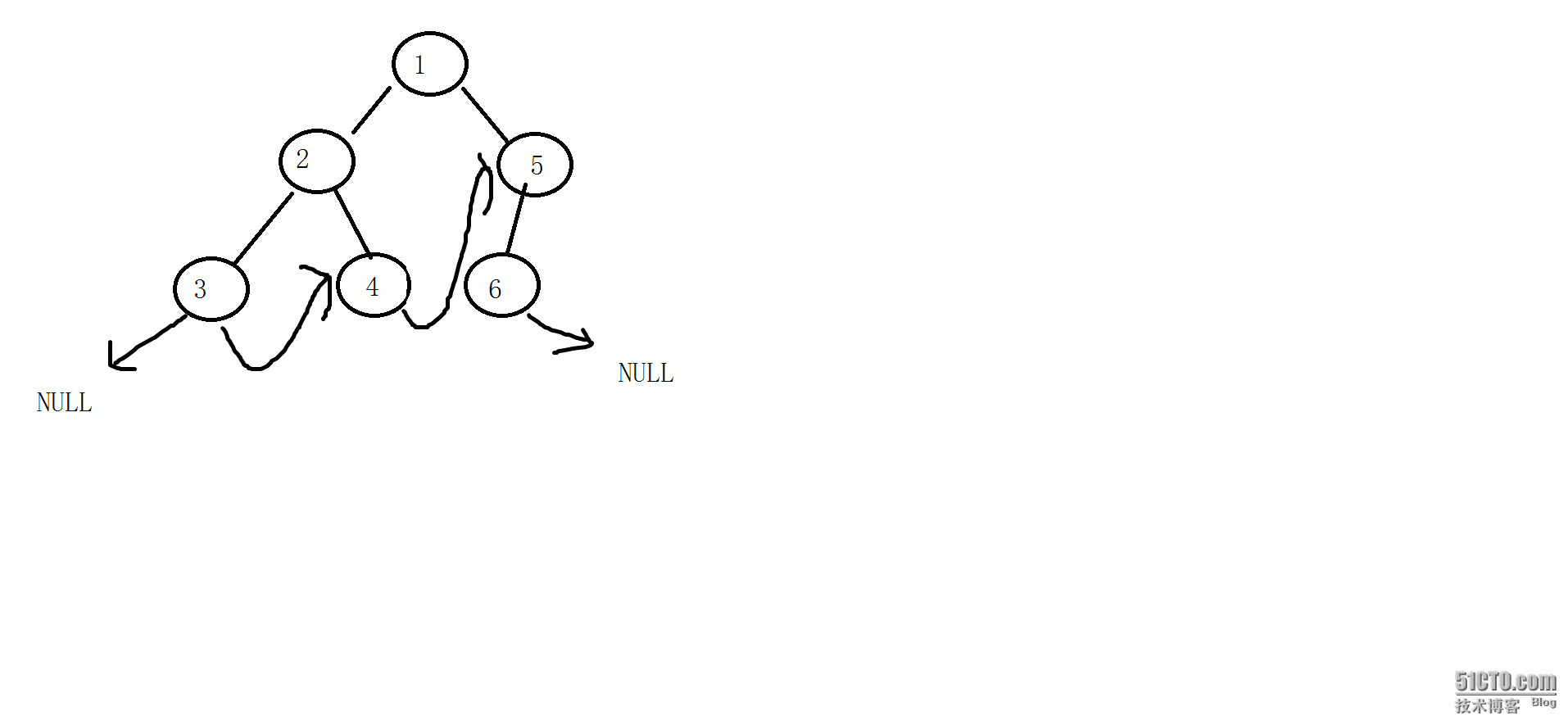 先序线索化
先序线索化
void _PrevorderThreading(BinaryTreeXsh<T> *cur, BinaryTreeXsh<T> *&prev)
{
if (cur == NULL)
{
return;
}
if (cur->_leftnode==NULL)
{
cur->_LeftTag=THREAD;
cur->_leftnode=prev;
}
if (prev&&prev->_rightnode==NULL)
{
prev->_RightTag = THREAD;
prev->_rightnode = cur;
}
prev = cur;
if (cur->_LeftTag == LINK)
{
_PrevorderThreading(cur->_leftnode, prev);
}
if (cur->_RightTag == LINK)
{
_PrevorderThreading(cur->_rightnode, prev);
}
}
 中序线索化
中序线索化
void _InorderThreading(BinaryTreeXsh<T>* root, BinaryTreeXsh<T> *&prev)
{
BinaryTreeXsh<T>*cur = root;
if (cur == NULL)
{
return;
}
_InorderThreading(cur->_leftnode, prev);
if (cur->_leftnode == NULL)
{
cur->_LeftTag = THREAD;
cur->_leftnode = prev;
}
if (prev&&prev->_rightnode == NULL)
{
prev->_RightTag = THREAD;
prev->_rightnode = cur;
}
prev = cur;
_InorderThreading(cur->_rightnode, prev);
}
 后序线索化
后序线索化
void _PostorderThreading(BinaryTreeXsh<T>*root, BinaryTreeXsh<T>*&prev)
{
BinaryTreeXsh<T>*cur = root;
if (cur == NULL)
{
return;
}
_PostorderThreading(cur->_leftnode, prev);
_PostorderThreading(cur->_rightnode, prev);
if (cur->_leftnode==NULL)
{
cur->_LeftTag = THREAD;
cur->_leftnode = prev;
}
if (prev&&prev->_rightnode == NULL)
{
prev->_RightTag = THREAD;
prev->_rightnode = cur;
}
prev = cur;
}
时间: 2024-10-16 16:36:39