SQL Server 其实从SQL Server 2005开始,也提供了类似ORACLE中固定执行计划的功能,只是好像很少人使用这个功能。当然在SQL Server中不叫"固定执行计划"这个概念,而是叫"执行计划指南"(Plan Guide 很多翻译是计划指南,个人觉得执行计划指南稍好一些)。当然两者虽然概念与命名不同,实质上它们所说的是相同的事情,当然商业包装是很常见的事情。个人还是觉得“固定执行计划”这个概念叫起来顺口,通俗易懂,执行计划指南(Plan Guide)叫起来老感觉非常拗口,不知所云(后面会在这两个概念切换,你知道我所说的是一件事情就好)。其实我以前也很少使用这些功能,直到最近在SQL Server 2014数据库中使用固定执行计划解决了几个SQL的性能问题,所以觉得还是有必要总结、归纳一下。
为什么要固定执行计划?
为什么要使用固定执行计划(Plan Guid)呢? 个人简单的从下面几个方面介绍一下,如有不足,敬请指正。个人也是在探索当中。
由于一些特殊原因(例如Parameter Sniffing、统计信息的变化或采样比例低造成的统计信息出现偏差、或其他像SQL Server 2014新的基数评估(Cardinality Estimator)特性引起优化器选择不合适的JOIN操作等等),导致某个SQL的执行计划出现很大偏差,当数据库优化器为SQL选择了一个糟糕的执行计划时,就可能出现严重性能问题,我就碰到过这样一个例子,在SQL Server 2014中,有一个SQL的执行频率较频繁,有时候优化器突然选择了一个较差的执行计划时,这时就会出现严重的性能问题。所以,这个时候,我们就必须使用Plan Guide固定这个执行计划,从而让优化器使用正确的执行计划,从而解决这样的性能问题。
另外一方面,因为优化器生成执行计划本身是很复杂的过程,我们所能干涉的不多,最多使用HINT提示来改变执行计划。而且优化器基于一些算法和开销考虑,也有可能生成的执行计划不是最优执行计划,而Plan Guid是DBA管理数据库的一件利器,如果你发现了一个比当前更好的执行计划,也能使用执行计划指南固定这个SQL的执行计划。当然这种情况非常、非常少,至少我在生产环境使用得不多。
有时候,某个系统是购买供应商的,你发现数据库里面有大量几乎相同的SQL解析,然后缓存了,其实你发现这些SQL完全可以只解析一次,完全可以参数化,没有必要大量解析。但是现在供应商没有提供技术支持了,不可能去优化代码里面的SQL语句,那么你也可以使用执行计划指南来帮你解决这个问题。
还有就是使用Plan Guide来调优,对比不同的执行计划的优劣。当然应该还有一些其它应用场景,只是我没有碰到过而已。
如何固定执行计划?
Plan Guide主要用到下面几个存储,关于这些系统存储过程的使用方法、功能介绍,官方文档有详细的介绍。在此就不画蛇添足了。
sys.sp_create_plan_guide,
sys.sp_create_plan_guide_from_handle,
sys.sp_control_plan_guide
下面我们还是看看一些应用场景案例吧!构造一个合适、贴切的例子实在是太花精力和时间,生产环境案例又不能搬出来,我们先来看看官方文档提供的例子吧,如下SQL所示,在测试数据库AdventureWorks2014,该SQL使用Nested Loop关联两个表
SELECT COUNT(*) AS c
FROM Sales.SalesOrderHeader AS h
INNER JOIN Sales.SalesOrderDetail AS d
ON h.SalesOrderID = d.SalesOrderID
WHERE h.OrderDate >= ‘20000101‘ AND h.OrderDate <=‘20050101‘;

假如(注意这里是假设)发现如果这个SQL中,两个表使用MERGE JOIN的方式,效率更高,那么我们可以使用sp_create_plan_guide来创建执行计划指南(固定执行计划),如下所示
EXEC sp_create_plan_guide
@name = N‘my_table_jon_guid‘,
@stmt = N‘SELECT COUNT(*) AS c
FROM Sales.SalesOrderHeader AS h
INNER JOIN Sales.SalesOrderDetail AS d
ON h.SalesOrderID = d.SalesOrderID
WHERE h.OrderDate >= ‘‘20000101‘‘ AND h.OrderDate <=‘‘20050101‘‘;‘,
@type = N‘SQL‘,
@module_or_batch = NULL,
@params = NULL,
@hints = N‘OPTION (MERGE JOIN)‘;
那么此时再执行这个SQL时,你就会发现执行计划就会变成Merge Join方式了。 这样好过在SQL Server中使用HINT,为什么呢? 有可能这个SQL是写死在应用程序里面,如果以后这个执行计划变成了一个糟糕的执行计划,维护的成本非常高(一方面如果没有记录,需要耗费精力去定位、查找这段SQL,另外一方面,DBA是没有权限接触这些应用程序代码的,可能需要你沟通、协调开发人员、运维人员。耗费无数的时间、精力.....,还有可能其他接手维护的人不了解情况等等),而使用执行计划指南,那么你查找、禁用、删除这个执行计划指南即可。非常方便、高效,也许你一分钟就能搞定,如果是Hint,说不定处理完,需要几天,想必这样的耗费精力沟通、协调的事情很多人都遇到过。
SELECT COUNT(*) AS c
FROM Sales.SalesOrderHeader AS h
INNER MERGE JOIN Sales.SalesOrderDetail AS d
ON h.SalesOrderID = d.SalesOrderID
WHERE h.OrderDate >= ‘20000101‘ AND h.OrderDate <=‘20050101‘;

另外,我们再来构造一个例子,模拟系统里面出现大量解析的SQL语句的案例,如下所示
USE AdventureWorks2014;
GO
SET NOCOUNT ON;
GO
DROP TABLE TEST
GO
CREATE TABLE TEST (OBJECT_ID INT, NAME VARCHAR(8));
GO
CREATE INDEX PK_TEST ON TEST(OBJECT_ID);
GO
DECLARE @Index INT =1;
WHILE @Index <= 10000
BEGIN
INSERT INTO TEST
SELECT @Index, ‘kerry‘;
SET @Index = @Index +1;
END
GO
UPDATE STATISTICS TEST WITH FULLSCAN;
GO
构造了上面案例后,我们清空该数据库所有缓存的执行计划(仅仅是为了干净的测试环境,避免以前缓存的执行计划影响实验结果),生产环境你不能使用DBCC FREEPROCCACHE清空所有缓存的执行计划,但是可以用DBCC FREEPROCCACHE删除特定的执行计划。
DBCC FREEPROCCACHE;
GO
然后我们开始测试我们的例子,假设系统里面有大量类似的SQL语句,数量惊人(我们仅仅测试四个)。如果这个系统是从供应商那里购买的,现在又没有技术支持和Support的人(或者及时有人Support,但是不严重影响使用的情况,人家不想花费精力去优化),没有人协助你优化这些SQL,你又不能将数据库参数“参数化”从简单设置为强制(因为影响太大,而且没有测试,不确定是否带来潜在的性能问题).....
SELECT * FROM TEST WHERE OBJECT_ID=1;
GO
SELECT * FROM TEST WHERE OBJECT_ID=2;
GO
SELECT * FROM TEST WHERE OBJECT_ID=3;
GO
SELECT * FROM TEST WHERE OBJECT_ID=4;
GO
....................................................................
此时查看执行计划,发现缓存了4个执行计划
SELECT qs.sql_handle,
qs.statement_start_offset,
qs.statement_end_offset,
qs.plan_handle,
qs.creation_time,
qs.execution_count,
qs.query_hash,
qs.query_plan_hash,
st.text,
qp.query_plan
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) AS st
CROSS APPLY sys.dm_exec_text_query_plan(qs.plan_handle, qs.statement_start_offset, qs.statement_end_offset) AS qp
WHERE text LIKE N‘%SELECT * FROM TEST WHERE OBJECT_ID%‘ AND text NOT LIKE ‘SELECT qs.sql_handle%‘;

那么此时,执行计划指南就能发挥其作用了,使用sp_create_plan_guide创建执行计划指南,强制SELECT * FROM TEST WHERE OBJECT_ID=xxx这样的SQL参数化
DECLARE @stmt nvarchar(max);
DECLARE @params nvarchar(max);
EXEC sp_get_query_template N‘SELECT * FROM TEST WHERE OBJECT_ID=1‘,
@stmt OUTPUT,
@params OUTPUT;
EXEC sp_create_plan_guide N‘my_sql_parameter_test‘,
@stmt,
N‘TEMPLATE‘,
NULL,
@params,
N‘OPTION(PARAMETERIZATION FORCED)‘;
然后我们执行下面命令,清空该数据库所有缓存的执行计划,然后执行上面四个SQL语句
DBCC FREEPROCCACHE;
GO
SELECT * FROM TEST WHERE OBJECT_ID=1;
SELECT * FROM TEST WHERE OBJECT_ID=2;
SELECT * FROM TEST WHERE OBJECT_ID=3;
SELECT * FROM TEST WHERE OBJECT_ID=4;
你会发现他们全部使用执行计划指南里面的执行计划了。不用多次解析了。

还是使用上面的例子,我们来解决一个Parameter Sniffing(参数嗅探)的问题,在实验前,我们先删除前面创建的Plan Guide,以免这个影响测试结果,
EXEC sp_control_plan_guide @operation=N‘DROP‘, @name=N‘my_sql_parameter_test‘;
我们构造一个数据倾斜的案例,这样方便我们演示
UPDATE dbo.TEST SET OBJECT_ID =1 WHERE OBJECT_ID <=2000;
UPDATE STATISTICS dbo.TEST WITH FULLSCAN;
然后我们创建一个简单的存储过程Proc_Parameter_Sniffing
CREATE PROCEDURE Proc_Parameter_Sniffing
( @Object_ID INT)
AS
BEGIN
SELECT * FROM TEST WHERE [email protected]_ID;
END
GO
接下来,我们清空缓存的执行计划,然后执行存储过程,参数为1
DBCC FREEPROCCACHE;
GO
EXEC Proc_Parameter_Sniffer 1;
然后我们查看这个存储过程的实际执行计划,如下所示,将Query_Plan这些XML拷贝出来并格式化

1 <Batch> 2 <Statements> 3 <StmtSimple StatementText="SELECT * FROM TEST WHERE [email protected]_ID" StatementId="1" StatementCompId="3" StatementType="SELECT" RetrievedFromCache="true" StatementSubTreeCost="0.0350227" StatementEstRows="2000" StatementOptmLevel="FULL" QueryHash="0xA99C3EB3A64627F3" QueryPlanHash="0x50042F73B31C8535" StatementOptmEarlyAbortReason="GoodEnoughPlanFound" CardinalityEstimationModelVersion="120"> 4 <StatementSetOptions QUOTED_IDENTIFIER="true" ARITHABORT="true" CONCAT_NULL_YIELDS_NULL="true" ANSI_NULLS="true" ANSI_PADDING="true" ANSI_WARNINGS="true" NUMERIC_ROUNDABORT="false"/> 5 <QueryPlan CachedPlanSize="16" CompileTime="0" CompileCPU="0" CompileMemory="152"> 6 <MemoryGrantInfo SerialRequiredMemory="0" SerialDesiredMemory="0"/> 7 <OptimizerHardwareDependentProperties EstimatedAvailableMemoryGrant="209715" EstimatedPagesCached="26214" EstimatedAvailableDegreeOfParallelism="2" MaxCompileMemory="3112816"/> 8 <RelOp NodeId="0" PhysicalOp="Table Scan" LogicalOp="Table Scan" EstimateRows="2000" EstimateIO="0.0238657" EstimateCPU="0.011157" AvgRowSize="19" EstimatedTotalSubtreeCost="0.0350227" TableCardinality="10000" Parallel="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row"> 9 <OutputList> 10 <ColumnReference Database="[AdventureWorks2014]" Schema="[dbo]" Table="[TEST]" Column="OBJECT_ID"/> 11 <ColumnReference Database="[AdventureWorks2014]" Schema="[dbo]" Table="[TEST]" Column="NAME"/> 12 </OutputList> 13 <TableScan Ordered="0" ForcedIndex="0" ForceScan="0" NoExpandHint="0" Storage="RowStore"> 14 <DefinedValues> 15 <DefinedValue> 16 <ColumnReference Database="[AdventureWorks2014]" Schema="[dbo]" Table="[TEST]" Column="OBJECT_ID"/> 17 </DefinedValue> 18 <DefinedValue> 19 <ColumnReference Database="[AdventureWorks2014]" Schema="[dbo]" Table="[TEST]" Column="NAME"/> 20 </DefinedValue> 21 </DefinedValues> 22 <Object Database="[AdventureWorks2014]" Schema="[dbo]" Table="[TEST]" IndexKind="Heap" Storage="RowStore"/> 23 <Predicate> 24 <ScalarOperator ScalarString="[AdventureWorks2014].[dbo].[TEST].[OBJECT_ID]=[@Object_ID]"> 25 <Compare CompareOp="EQ"> 26 <ScalarOperator> 27 <Identifier> 28 <ColumnReference Database="[AdventureWorks2014]" Schema="[dbo]" Table="[TEST]" Column="OBJECT_ID"/> 29 </Identifier> 30 </ScalarOperator> 31 <ScalarOperator> 32 <Identifier> 33 <ColumnReference Column="@Object_ID"/> 34 </Identifier> 35 </ScalarOperator> 36 </Compare> 37 </ScalarOperator> 38 </Predicate> 39 </TableScan> 40 </RelOp> 41 <ParameterList> 42 <ColumnReference Column="@Object_ID" ParameterCompiledValue="(1)"/> 43 </ParameterList> 44 </QueryPlan> 45 </StmtSimple> 46 </Statements> 47 </Batch> 48 </BatchSequence> 49 </ShowPlanXML>
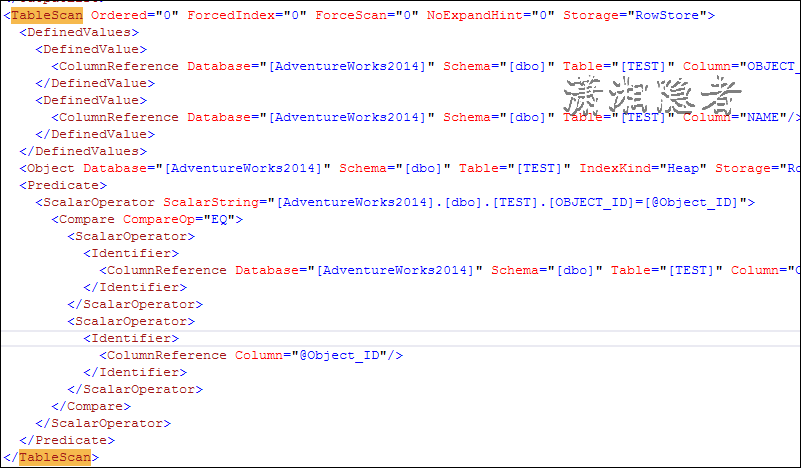
如下所示,目前它确实是使用准确的执行计划,进行全表扫描(TableScan),如果此时使用其它参数(例如下面SQL),就会出现Parameter Sniffer(参数嗅探)问题,这个是因为SQL Server在处理存储过程的时候,是一次编译,多次重用,执行计划重用。所以当参数为2500的时候,执行计划依然是进行全表扫描(TableScan),这个时候,全表扫描显然是一个糟糕的执行计划。
EXEC Proc_Parameter_Sniffer 2001;
而且,大部分数据应该做Index Seek是一个较优的执行计划,只有Object_ID=1这样的特殊数据,全部扫描才是一个较优的执行计划,假如实际使用环境中,也很少用到Object_ID=1这样的查询,那么我们可以固定执行计划,让其使用参数2001的执行计划
EXEC sp_create_plan_guide
@name = N‘parameter_sniffing_guid‘,
@stmt = N‘SELECT * FROM TEST WHERE [email protected]_ID‘,
@type = N‘OBJECT‘,
@module_or_batch =N‘Proc_Parameter_Sniffing‘,
@params = NULL,
@hints = N‘OPTION(optimize for(@Object_ID=2001))‘;
然后我们再次调用EXEC Proc_Parameter_Sniffer 1;时,你会发现该SQL的执行计划变更为索引查找了。

当然实际生产环境中,情况往往比较复杂,绝不可能有这么简单、理想的环境出现,往往还需要根据实际情况、权衡利弊,多方考虑才能指定一个折中的方案。具体问题具体分析、不能依葫芦画瓢。理论要结合实际情况。
查看执行计划指南
查看执行计划指南非常信息非常简单,你只需要查询sys.plan_guides即可。
SELECT * FROM sys.plan_guides;
另外,启用、禁用、删除执行计划指南都是通过一个系统存储过程sys.sp_control_plan_guide来实现的,使用非常简单。下面仅仅简单举几个例子。sys.sp_control_plan_guide的存储过程如下,实际上它都是封装调用了sys.sp_control_plan_guide_int的功能
SET QUOTED_IDENTIFIER ON
SET ANSI_NULLS ON
GO
create procedure sys.sp_control_plan_guide
@operation nvarchar(60),
@name sysname = NULL
as
BEGIN TRANSACTION
declare @return_code int
if( lower(@operation) = ‘drop‘ OR lower(@operation) = ‘enable‘ OR lower(@operation) = ‘disable‘)
exec @return_code = @operation, @name
else
exec @return_code = sys.sp_control_plan_guide_int @operation
if( @return_code = 0 )
begin
if( lower(@operation) = ‘drop‘ OR lower(@operation) = ‘drop all‘)
begin
EXEC %%System().FireTrigger(ID = 238, ID = 27, ID = 0, ID = 0, Value = @name,
ID = -1, ID = 0, ID = 0, Value = NULL, ID = 2,
Value = @operation, Value = @name, Value = NULL, Value = NULL, Value = NULL, Value = NULL, Value = NULL)
end
else
begin
EXEC %%System().FireTrigger(ID = 216, ID = 27, ID = 0, ID = 0, Value = @name,
ID = -1, ID = 0, ID = 0, Value = NULL, ID = 2,
Value = @operation, Value = @name, Value = NULL, Value = NULL, Value = NULL, Value = NULL, Value = NULL)
end
end
COMMIT TRANSACTION
GO
禁用执行计划指南
1:禁用名字为my_sql_plan_test的执行计划指南
USE AdventureWorks2014;
GO
EXEC sp_control_plan_guide @operation=N‘DISABLE‘, @name=N‘my_sql_plan_test‘
2:禁用所有的执行计划指南
USE AdventureWorks2014;
GO
EXEC sys.sp_control_plan_guide @operation = N‘DISABLE ALL‘;
确切的说,应该是禁用数据库AdventureWorks2014下所有的执行计划指南。
启用执行计划指南
1:启用名字为my_sql_plan_test的执行计划指南
USE AdventureWorks2014;
GO
EXEC sp_control_plan_guide @operation=N‘ENABLE‘, @name=N‘my_sql_plan_test‘;
2:启用所有的执行计划指南
USE AdventureWorks2014;
GO
EXEC sys.sp_control_plan_guide @operation = N‘ENABLE ALL‘;
确切的说,应该是启用数据库AdventureWorks2014下所有被禁用的执行计划指南。
删除执行计划指南
删除执行计划指南非常简单,如下所示
我们首先查看有执行计划指南,找到想要删除的Plan Guide,例如,我们想删除命名为my_sql_plan_test的执行计划指南。
EXEC sp_control_plan_guide @operation=N‘DROP‘, @name=N‘my_sql_plan_test‘;
参考资料:
https://technet.microsoft.com/zh-cn/library/ms188255(v=sql.105).aspx
https://technet.microsoft.com/zh-cn/library/bb964726(v=sql.105).aspx
https://msdn.microsoft.com/zh-cn/library/ms179880.aspx
原文地址:https://www.cnblogs.com/lonelyxmas/p/9411433.html