一、elasticsearch index 索引流程
步骤:
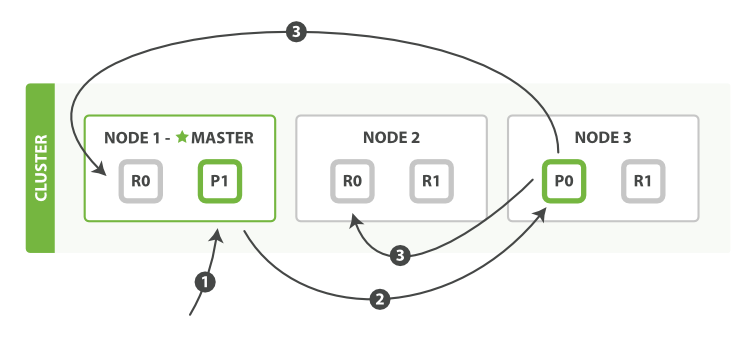
客户端向Node1 发送索引文档请求
Node1 根据文档ID(_id字段)计算出该文档应该属于shard0,然后请求路由到Node3的P0分片上。
Node3在P0上执行了请求。如果请求成功,则将请求并行的路由至Node1,Node2的R0上。当所有的Replicas报告成功后,Node3向请求的Node(Node1)发送成功报告,Node1再报告至Client。
当客户端收到执行成功后,操作已经在Primary shard和所有的replica shards上执行成功了

二、 elasticsearch 数据读取流程
1.客户端发送Get请求到NODE1。
2.接着NODE1使用文档的_id决定文档属于R0 分片,然后获取R0的所有副本的地址。这次,它将请求路由至NODE2。
3.NODE2将文档返回给NODE1,NODE1将文档返回给客户端。 对于读请求,请求节点(NODE1)将在每次请求到来时都选择一个不同的replica。
shard来达到负载均衡。使用轮询策略轮询问所有的replica shards。

三、 elasticsearch 数据更新流程
1.客户端发送更新操作请求至NODE1
2.NODE1将请求路由至NODE3,Primary shard所在的位置
3.NODE3从P0读取文档,改变source字段的JSON内容,然后试图重新对修改后的数据在P0做索引。如果此时这个文档已经被其他的进程修改了,那么它将重新执行3步骤,这个过程如果超过了retryon_conflict设置的次数,就放弃。
4.如果NODE3成功更新了文档,它将并行的将新版本的文档同步到NODE1和NODE2的replica shards重新建立索引。一旦所有的replica
shards报告成功,NODE3向被请求的节点(NODE1)返回成功,然后NODE1向客户端返回成功。

四、 elasticsearch 删除数据
(流程和数据索引类似,删除只是标记这个文档不可用,并不是立即删除)
客户端向 Node 1 发送删除请求。
节点使用文档的 _id 确定文档属于分片 0 。请求会被转发到 Node 3`,因为分片 0 的主分片目前被分配在 `Node 3 上。
Node 3 在主分片上面执行请求。如果成功了,它将请求并行转发到 Node 1 和 Node 2 的副本分片上。一旦所有的副本分片都报告成功, Node 3 将向协调节点报告成功,协调节点向客户端报告成功。
原文地址:https://www.cnblogs.com/unnunique/p/9376678.html