介绍一下NFS的安装,以及共享文件
NFS(Net File
System),通过使用NFS,可以像使用本地文件一样访问远程文件。
它主要解决了数据共享的问题,可以备份容灾。
安装配置
1.以linux ubuntu为例,做nfs
server的机器和
nfs client的机器分别安装
"nfs
server"
|
1 |
sudo apt-get install nfs-kernel-server |
"nfs
client"
|
1 |
sudo apt-get install nfs-common |
2.配置nfs需要共享的目录,在 /etc/exports 最下面添加需要共享的目录 /home/hadoop/yxlShare
/etc/exports
|
1 |
/home/hadoop/yxlShare *(rw,sync,no_root_squash) |
3.重启 portmap和 nfs server
|
1 2 |
sudo /etc/init.d/portmap restart sudo /etc/init.d/nfs-kernel-server restart |
4.运行一下命令,查看一下可以被挂载的情况
|
1 |
showmount -e |
5.此时,在客户端上,将一个本地目录挂载到nfs的共享目录上,把它视为本地目录。
可以再添加fstab,让linux开机自动挂载
用法: sudo
mount nfsServer的ip:共享目录 本地目录
示例
|
1 |
sudo mount 192.168.1.111:/home/hadoop/.ssh /home/hadoop/.ssh |
4.此时,无论在client上还是server上,对这个目录的修改,都能反映出来,这样多台机器就共享了一个目录。
实例
1.共享hadoop
ssh授权文件
当整个hadoop集群,共享一个authorized_keys,以便ssh跳转。就可以将本地目录 ~/nfs_share/ ,挂载在nfs上。
然后建立软连接,这样就实现了共享。
|
1 |
ln -s ~/nfs_share/authorized_keys ~/.ssh/authorized_keys |
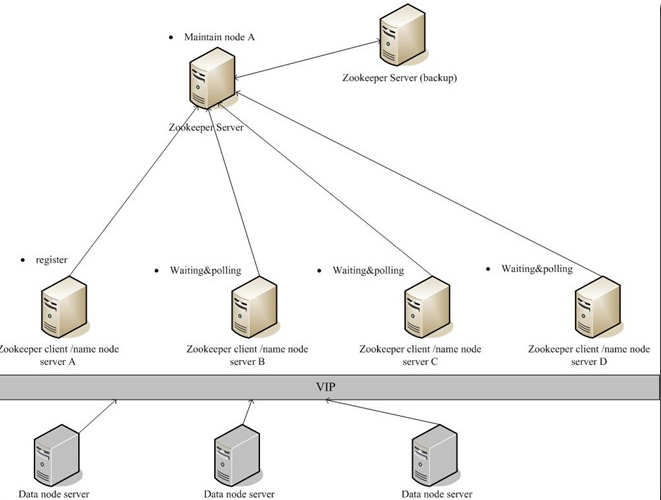
2.namenode
HA 元数据保存
大家都知道hadoop的namenode是单点。但结合zookeeper和nfs,就可以实现自动切换的功能。
将namenode的元数据保存在nfs,当namenode这台机器挂掉了,利用zookeeper再找一个替补机器,然后替补机器读取nfs上的元数据,即成为了namenode。
这里有一个图,说明了情况. 引用自http://www.cnblogs.com/commond/archive/2009/07/28/1533223.html