目的:
通过用Mlpconv层来替代传统的conv层,可以学习到更加抽象的特征。传统卷积层通过将前一层进行了线性组合,然后经过非线性激活得到(GLM),作者认为传统卷积层的假设是基于特征的线性可分。而Mlpconv层使用多层感知机,是一个深层的网络结构,可以近似任何非线性的函数。在网络中高层的抽象特征代表它对于相同concept的不同表现具有不变性(By abstraction we mean that the feature is invariant to the variants of the same concept)。微小的神经网络在输入的map上滑动,它的权值是共享的,而且Mlpconv层同样可以使用BP算法学习到其中的参数。传统卷积层(左)与Mlpcon层(右)对比如下:
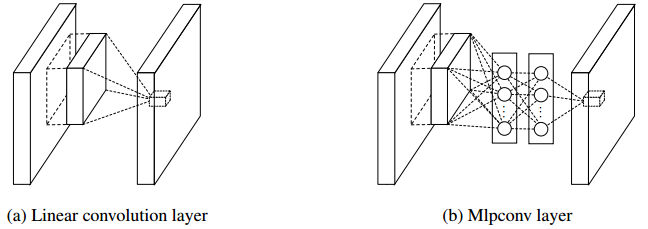
实现:
对于非线性激活函数,例如一个ReLU函数有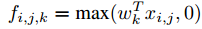 ,k代表通道下标,Xij表示以像素(i,j)为中心的输入区域。在Mlpconv层中,每一个神经元计算的规则为
,k代表通道下标,Xij表示以像素(i,j)为中心的输入区域。在Mlpconv层中,每一个神经元计算的规则为
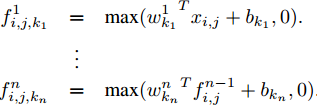
n代表网络的层次。在上述b图可以看到,对于每一个神经元,生成的只有单个输出,而输入是多维(可以理解为多通道,在网络中的每一层是一个1*k的向量),可以把整个过程看作是一个1*1*k的卷积层作用在k通道上。在后续的一些论文中,常用到这样的方法来对输入进行降维(不是对图像的输入空间,而是通道降维),这样的非抽象的过程可以很好地把多维信息压缩。
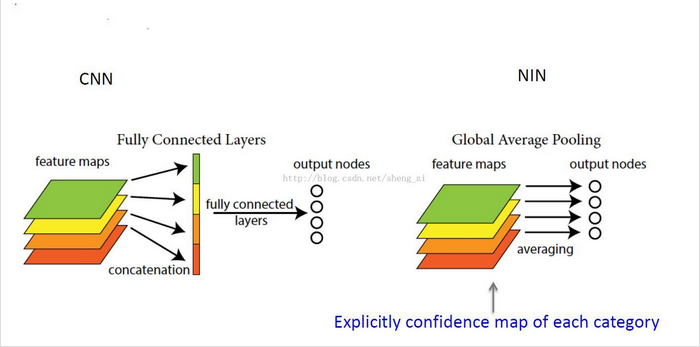
使用全局平均池化层代替FC层:
使用这样的微网络的结构,可以抽象出更加好的局部特征,使得特征图与类别有一致性。在softmax的前一层去除FC层,则在这一层没有参数的优化,可以减少计算的消耗,降低这一层的过拟合。
过程是这样的:对于每一个特征图计算它的平均数,然后把这些平均数组成一个特征向量,输入到后续的softmax层中。
如下图:
总结NIN的优点:
(1)更好的局部抽象
(2)去除全连接层,更少的参数
(3)更小的过拟合