原创 2017-08-29 晓风轻 程序猿DD
——请先阅读这3篇文章:
- 程序员你为什么这么累?
- 我的编码习惯 - 接口定义
- 我的编码习惯 - Controller规范
开发中日志这个问题,每个公司都强调,也制定了一大堆规范,但根据实际情况看,效果不是很明显,主要是这个东西不好测试和考核,没有日志功能一样跑啊。
但编程活久见,开发久了,总会遇到“这个问题生产环境上能重现,但是没有日志,业务很复杂,不知道哪一步出错了?” 这个时候,怎么办? 还能怎么办,发个版本,就是把所有地方加上日志,没有任何新功能,然后在让用户重现一遍,拿下日志来看,哦,原来是这个问题。
有没有很熟悉的感觉?

还有一种情况,我们系统有3*5=15个节点,出了问题找日志真是痛苦,一个一个机器翻,N分钟后终于找到了,找到了后发现好多相似日志,一个一个排查;日志有了,发现逻辑很复杂,不知道走到哪个分支,只能根据逻辑分析,半天过去了,终于找到了原因。。。一个问题定位就过去了2个小时,变更时间过去了一半。。。

所以我对日志的最少有以下2点要求:
- 能找到那个机器
- 能找到用户做了什么
针对第一点,我修改了一下nginx的配置文件,让返回头里面返回是哪个机器处理的。
nginx的基本配置,大家查阅一下资料就知道。简单配置如下(生产环境比这个完善)
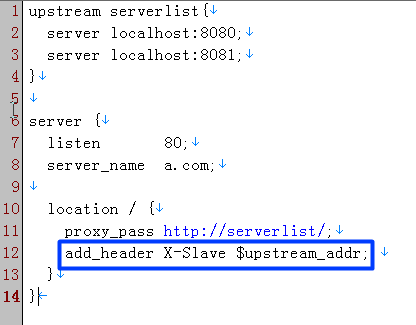
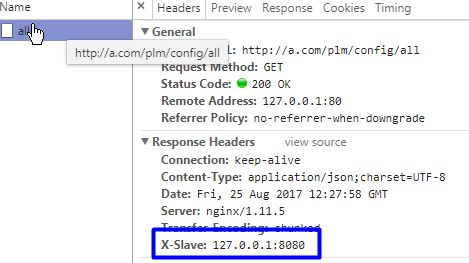
效果如图,返回了处理的节点:
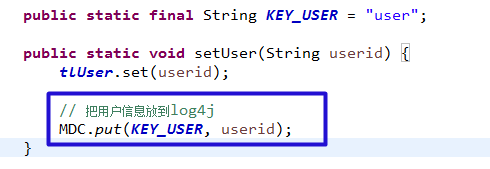
第二点,要知道用户做了什么。用户信息是很重要的一个信息,能帮助海量日志里面能快速找到目标日志。一开始要求开发人员打印的时候带上用户,但是发现这个落地不容易,开发人员打印日志都经常忘记,更加不用说日志上加上用户信息,我也不可能天天看代码。所以找了一下log4j的配置,果然log4j有个叫MDC(Mapped Diagnostic Context)的类(技术上使用了ThreadLocal实现,重点技术)。具体使用方法请自行查询。具体使用如下:
filter中得到用户信息,并放入MDC,记住filter后要清理掉(因为tomcat线程池线程重用的原因)。

用户信息放入MDC:
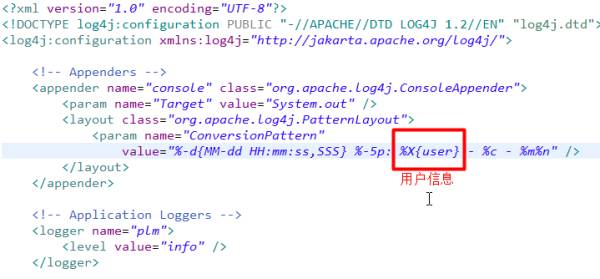
log4j配置,增加用户信息变量:
我做好上面2步后,对开发人员的日志只有3点要求:
1. 修改(包括新增)操作必须打印日志
大部分问题都是修改导致的。数据修改必须有据可查。
2. 条件分支必须打印条件值,重要参数必须打印
尤其是分支条件的参数,打印后就不用分析和猜测走哪个分支了,很重要!如下面代码里面的userType,一定要打印值,因为他决定了代码走哪个分支。
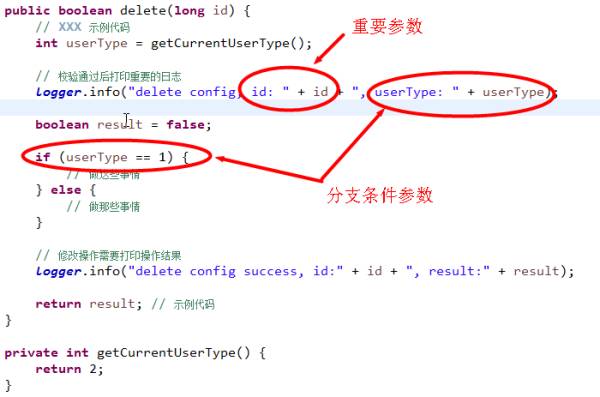
3. 数据量大的时候需要打印数据量
前后打印日志和最后的数据量,主要用于分析性能,能从日志中知道查询了多少数据用了多久。这点是建议。自己视情况而决定是否打印,我一般建议打印。
加上一篇AOP,最后的日志如下:

其实日志的级别我到不是很关注,还没有到关注这步到时候。开发组长需要做好后勤工作(前面2步),然后制定简单规则,规则太多太能落实了。
日志这个东西,更多是靠自觉,项目组这么多人,我也不可能一个一个给大家看代码,然后叫你加日志。我分析了一下,为什么有些人没有打印日志的习惯,说了多次都改不过来。我建议大家养成下面的习惯,这样你的日志就会改善多了!
1. 不要依赖debug,多依赖日志。
别人面对对象编程,你面对debug编程。有些人无论什么语言,最后都变成了面对debug编程。哈哈。这个习惯非常非常不好!debug会让你写代码的时候偷懒不打日志,而且很浪费时间。改掉这个恶习。
2. 代码开发测试完成之后不要急着提交,先跑一遍看看日志是否看得懂。
日志是给人看的,只要热爱编程的人才能成为合格程序员,不要匆匆忙忙写完功能测试ok就提交代码,日志也是功能的一部分。要有精益求精的工匠精神!
日志规范想不到写了这么多,不容易啊。觉得有帮助请点赞加关注,其他规范敬请期待!更多内容请持续关注!
推荐阅读
- 程序员你为什么这么累?
- 程序员你为什么这么累[续]:编码习惯之接口定义
- Logback+ELK+SpringMVC搭建日志收集服务器
- 在Pivotal Web Service上发布Spring Boot应用
- Spring Cloud构建微服务架构:服务网关(基础)【Dalston版】