MongoDB报表实例方案选型
背景介绍
在我们的生产环境使用的是复制集,为了将数据库服务器的业务压力分摊,我们将数据库拆分到了不同的复制集上运行。
我们在MongoDB复制集上运行应用程序,有时候有报表需求,常规用途是获得用户行为的分析,还有其他商业定制指标数据;有搜索引擎的查询需求,使用Solr从oplog.rs获取增量数据更新产品信息的索引。
这些报表查询和搜索引擎的查询需求,尽量不能影响到线上的业务正常运行,因此不能直接在生产数据库上运行报表。经过开发和运维讨论之后,在项目成立之初,计划隔断报表任务以致不会影响到生产任务。
来谈谈混淆生产和报表的问题
工作集(workingset),是MongoDB在任何的时间间隔读取和写入的整个数据库的一个子集。生产环境中的活跃用户操作文档数据,操作系统将它们保持在物理内存中。
注意:不要让你的工作集增长大过内存!可以使用MongoDB的监控服务Cloud Manager监控你的实例。如果确实出现这个问题,你需要分片,因此容量规划是很重要的,可以作为独立的专题来讲。即使数据库大小是可用内存的数百或数千倍,如果你在前期合理规划了架构并优化了索引,MongoDB同样也能高效运行。在工作集外的数据会保持和磁盘上一致,当用户空闲时,他们操作的文档将会不再使用,所占用的内存用于新的活跃用户的内存请求。
报表应用会查询大量的数据,一般不会重复访问相同的数据,每个报表应用可能完全访问不同的数据集合。这意味着需要持续提供内存给新的文档读取请求。如果你将报表应用和生产应用放在相同的实例上运行,报表应用将会与你的生产应用争夺内存,持续不断地请求活跃用户的数据,而你的生产应用持续不断的加载它(getmore)。那么数据库服务器性能将发生波动。
报表应用,将会有大量count、aggregate、mapReduce等聚合操作,这些操作对于MongoDB来说效率不高,因此将它与生产任务分开是一个好的做法。
使用专属报表实例的复制集
MongoDB复制集具有在线持久性,通过复制数据到一个集合中的所有节点,并对客户端提供无缝的故障转移。包含一个主节点提供写,而剩下的是只读副本。当条件需要的时候选举决定哪个节点是主。复制集应该包含一个奇数成员帮助快速选举。
判断不可达的机器是否宕机基本上无法判断,有可能被网络被分区了。因此如果复制集中的大多数节点下线了(也就是说,3个成员中的2个下线),即使一个健康的主节点保留,它会降级为一个只读的副本。不这么做可能导致多个机器在一个网络分区的情况下定义它们自己为主节点,出现多个主节点,导致可怕的数据不一致。
因此一个复制集包含至少3个成员,提供一个机器失败的错误容忍。
在MongoDB官方的文档中,推荐限制报表查询到专属节点。报表基本不需要写操作,而是统计最终一致性数据。如果提取的数据有秒级或分级延时,每日的报表是不允许的。如果你的计数统计丢失了一些操作,这将导致报表数据不准确。
你可以在MongoDB复制集环境构建专属的报表节点,方案有隐藏的复制集成员hidden member或者读偏好read preference设置相关的标签集合tag sets。第一种方法更简单,第二种方法更灵活。
下图是使用专属节点提供报表需求的架构图:

隐藏成员方案
参考:https://docs.mongodb.com/manual/tutorial/configure-a-hidden-replica-set-member/
隐藏成员是复制集的一部分,但是不能成为主,并且对客户端应用程序不可见。隐藏成员可以在选举中投票。
一个复制集的隐藏成员被配置为priority: 0,是为了阻止它们被选举为主。设置hidden: true,即使他们指定了一个读偏好为secondary,也会阻止客户端连接到复制集路由读操作到它。
从一个隐藏成员读数据,你只能通过直连该隐藏成员访问,并指定slave_ok,而不能通过MongoReplicaSetClient类。
隐藏成员设置
你可以使用mongo shell来隐藏一个存在复制集的成员:
$ mongo admin -uxucy -p
PRIMARY> conf = rs.config()
{ "_id" : "test", "version" : 21, "members" : [ { "_id" : 0, "host" : "xucy.local:27017", }, { "_id" : 1, "host" : "xucy.local:28017", }, { "_id" : 2, "host" : "xucy.local:29017", } ] }
PRIMARY> conf.members[1].priority = 0
PRIMARY> conf.members[1].hidden = true
PRIMARY> conf.version += 1
PRIMARY> rs.reconfig(conf)
xucy.local:28017现在隐藏了,它将继续复制操作和像往常一样在选举中投票,但是连接到复制集的客户端将不会从它读取,即使xucy.local:29017下线。
Ruby版的报表应用连接代码示例:
require ‘mongo‘
reporting = Mongo::MongoClient.new("xucy.local", "28017", slave_ok: true)
reporting[‘my_application‘][‘users‘].aggregate(...)
限制说明
使用隐藏的成员是一个最简单的方式,配置实例用于专属的工作负载,像报表和搜索引擎访问,然而使用上有一些限制需要说明的。
隐藏成员不能在紧急情况下读取
带有2个普通和1个隐藏成员在一个复制集中,对于写的错误容忍等价于一个常规的3个成员的集合。然而,你失去两个节点,你的生产应用将不能优雅的降级到只读模式,因为你的隐藏成员将不允许复制集客户端读取。如果你只是喜欢隐藏成员访问简单,土豪方案是使用一个5成员(带有一个隐藏成员)的复制集。
对于复制集的包装代码不能被使用
很多团队创建应用定制的包装代码时,使用MongoDB驱动提供的复制集连接访问方法,添加复制集连接的基本信息给客户端。因为你需要使用独立连接到你的报表实例,你不能重用它。
标签成员方案
参考:https://docs.mongodb.com/manual/tutorial/configure-replica-set-tag-sets/
标签成员,更加复杂,但是,是更灵活的方法,用于路由报表查询到一个专属节点去使用标签和读偏好。
设置一个成员为priority: 0,阻止它被选举为主,但是不设置它为隐藏,分配一个标签use: reporting:
PRIMARY> conf = rs.config()
{ "_id" : "test", "version" : 21, "members" : [ { "_id" : 0, "host" : "xucy.local:27017", }, { "_id" : 1, "host" : "xucy.local:28017", }, { "_id" : 2, "host" : "xucy.local:29017", } ] }
PRIMARY> conf.members[1].priority = 0
PRIMARY> conf.members[1].tags = { "use": "reporting" }
PRIMARY> conf.version += 1
PRIMARY> rs.reconfig(conf)
在这种情况下,xucy.local:28017绝不会成为主。然而,当其他两个机器变得不可达,你的应用还能处理读请求到报表服务器。它会继续运行,不会导致你的报表应用在这样一个事件期间暂停。
Python版报表应用连接代码示例:
from pymongo import MongoReplicaSetClient
from pymongo.read_preferences import ReadPreference
rep_set = MongoReplicaSetClient( ‘xucy.local:27017,xucy.local:28017,xucy.local:29017‘, replicaSet = ‘test‘, read_preference = ReadPreference.SECONDARY, tag_sets = [{‘use‘:‘reporting‘}] )
rep_set.my_application.users.aggregate(...)
对于报表应用来说,在主可用的情况下,确保尽量不要在剩下的唯一的辅助成员上运行报表应用,因为这样将报表和生产混合在一起了。
以上只发送报表查询到标记有use: reporting的辅助成员,并且如果没有可用的主,我们应该从根本上阻止继续运行。在实践中,如果你发现没有主,你应该抛出异常并在你的扩展代码中处理它们。还要做好状态的监控,如:reporting_system.ok()。当发现异常时进行分支处理。
益处和考虑
使用标签和读偏好相对隐藏成员来说,带来一定的灵活性。
容易添加报表实例
因为你的连接代码是可定义的,而不是指定到一个专门的主机。你可以添加更多节点为报表实例,只需要添加并标记他们,像这样:
PRIMARY> rs.add({_id:3, host:"xucy.local:30017", priority:0, tags:{‘use‘:‘reporting‘}})
你原来的代码将会利用到新的报表实例,并且复制集将继续运行,不用触发选举和从客户端断开连接。
报表实例可以被跳过或删除
当你想将目前使用的报表实例提供给其他应用时,报表标记在必要时可以被移动,或者移除。像这样的一个重新配置将会触发选举,并重连所有客户端,这是可以接受的。注意:这是一个逆向的方法,通过增加常用生产可用实例,分发生产读到副本成员。
一些驱动需要手工同步
检查你的驱动文档,例如,Ruby驱动(像1.9.2),不会刷新副本集的视图,除非客户端像这样使用refresh_mode: :sync显式初始化。
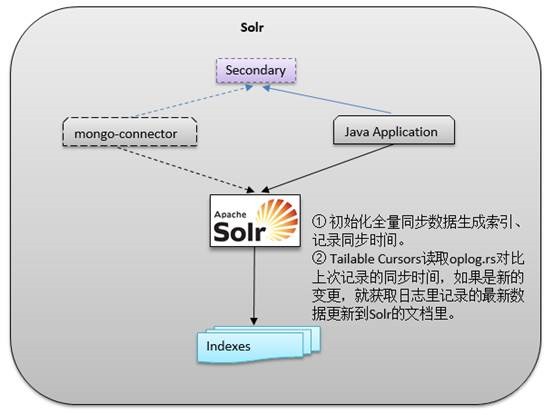
Solr生成全文索引
MongoDB复制集配置简单、容易上手是我喜欢MongoDB的原因之一。对于MongoDB报表实例,无论你使用隐藏成员还是标签成员,开发和部署都非常简单。我们在生产环境也将报表实例用于Solr生成全文索引。
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
读取报表实例的方案选型
期初的方案是使用mongo-connector集成MongoDB到Solr实现增量索引。(http://ultrasql.blog.51cto.com/9591438/1696083/)
mongo-connctor是一款用于同步MongoDB数据到其他系统组件,比如它能同步数据到Solr、ElasticSearch或者其他MongoDB集群中去。它的实现原理是依据MongoDB的Replica Set复制模式,通过分析oplog日志文件达到最终的同步目的。安装配置启动过程可参考 官方文档 。
由于是单进程版本的,效率对我们当时来说不高,如果能改成利用多核性能的话可能好些。
MongoDB Tailable Cursors
MongoDB 有一个叫 Tailable Cursors的特性,它类似于tail -f 命令,你在一个Capped Collection上面执行查询操作,当操作完成后,你可以不关闭返回的数据Cursor,并持续地从中读出新加入的数据。
在高写入的Capped Collection上,索引不可用时,可使用Tailable Cursors。例如,MongoDB复制使用了Tailable Cursors来获取Primary的尾oplog日志。
考虑以下与Tailable Cursors相关的行为:
- Tailable Cursors不使用索引,并以自然排序返回文档。
- 因为Tailable Cursors不使用索引,查询的初始扫描非常耗性能;但是,游标初始化完后,随后获取到的新增加的文档是很快速的。
- Tailable Cursors如果遇到以下情况之一将会僵死或无效:
- 查询无匹配结果。
- 游标在集合尾部返回文档,随后应用程序删除了该文档。
僵死的游标id为0。
DBQuery.Option.awaitData
在使用TailableCursor时,此参数会在数据读尽时先阻塞一小段时间后再读取一次并进行返回。
跟踪oplog的示例:
use local
var cursor = db.oplog.rs.find({"op" : "u", "ns" : "MyDB.Product"},{"ts": 1, "o2._id": 1}).addOption(DBQuery.Option.tailable).addOption(DBQuery.Option.awaitData);
while(cursor.hasNext()){
var doc = cursor.next();
printjson(doc);
};
2.6版的游标方法:
cursor.addOption()
https://docs.mongodb.com/v2.6/reference/method/cursor.addOption/
3.2版的游标方法:
cursor.tailable()
https://docs.mongodb.com/manual/reference/method/cursor.tailable/
我们根据该特性,开发了Java应用程序,先初始化全量同步数据到Solr生成索引、记录同步时间。然后通过Tailable Cursors读取oplog.rs对比上次记录的同步时间,如果是新的变更,通过新的进程异步获取日志里记录的最新数据更新到Solr的文档里。