grep 全名为 全面搜索正则表达式并把行打印出来(global search regular expression)
grep搜索以 FILE 命名的文件输入 (或者是标准输入,如果没有指定文件名,或者给出的文件名是 - 的话),寻找含有与给定的模式 PATTERN(正则表达式) 相匹配的内容的行。默认情况下, grep 将把含有匹配内容的行打印出来。
另外,也可以使用两个变种程序 egrep 和 fgrep 。 Egrep 与 grep -E 相同。 Fgrep 与 grep -F 相同
grep的用法: 命令参数详解参考
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
grep与egrep的常用选项(OPTIONS):
演示文本
aaat
bbb
ttt
BBB
-i:忽略大小写

-o:显示匹配到的内容

-v:反向选取

-A #:匹配到的行的下#行

-B #:匹配到的行的上#行

-C #:匹配到行的上下各#行

--color=auto:匹配的显示颜色

-n:显示行号

grep与egrep的模式(PATTERN):

字符匹配
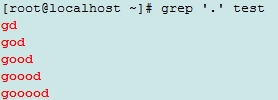
演示文本
gd
god
good
goood
gooood
grep演示
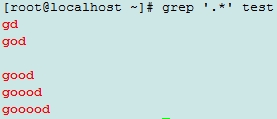
. :可以匹任意单个单词
集合相关
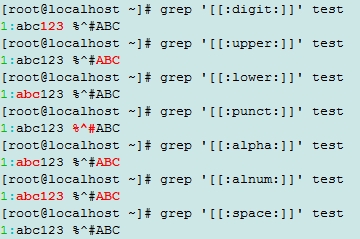
演示文本
abc123 %^#ABC
grep演示
匹配到集合中的相关内容

egrep演示

次数匹配
演示文本
gd
god
good
goood
gooood
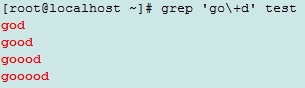
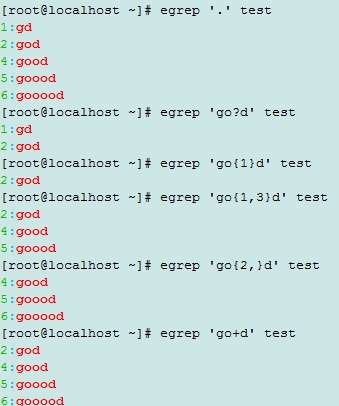
\?:匹配前面的字符0次或1次
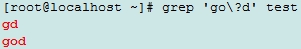
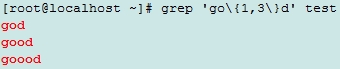
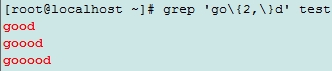
\{m\}: 匹配其前面的字符m次;

\{m,n\}:匹配其前面的字符至少m次,至多n次;
\{m,\}:匹配其前面的字符至少m次
\+:匹配前面的字符至少1次 与\{1,\}效果一样
.*:匹配任意长度的任意字符,连空格行也匹配出来了
egrep演示
位置锚定
演示文本
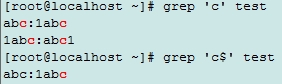
abc:1abc
1abc:abc1
grep演示
^: 行首锚定

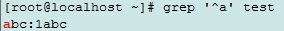
$: 行尾锚定
^$: 空白行
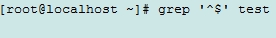
\<: 词首锚定, \b
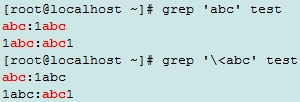
\>:词尾锚定,\b
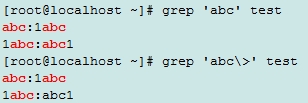
\<pattern\>匹配单词
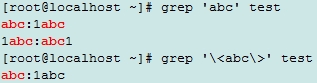
egrep演示
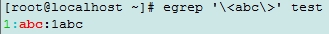
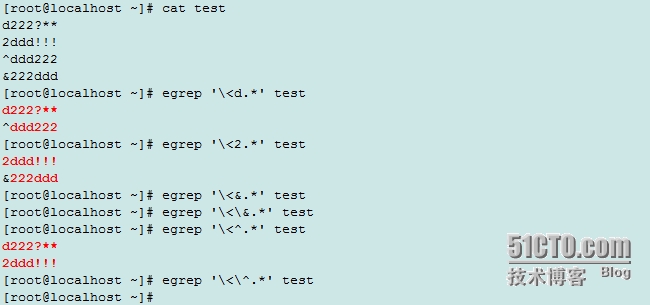
通过一下演示可以表明词首或词尾锚定只能锚定数字和字母,字母和数字连在一起相当于一个单词
分组,或
演示文本
qqgodrrrgoogle
dddgooglerrrgod
godee
googlerrrgod
grep演示
加和不加分组括号没什么区别

加完后前面再加一个"^",只能显示行首锚定的god和google

不加分组括号,只能显示行首锚定god的和所有行有google的
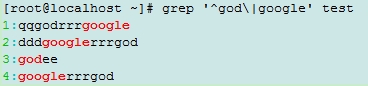
egrep演示
后向引用 \1, \2, \3:
模式自左而右,后向引用:模式中,如果使用\(\)实现了分组,在某行文本的检查中,如果\(\)的模式匹配到了某内容,此内容后面的模式中可以被引用;引用第#个左括号以及与其匹配右括号之间的模式匹配到的内容
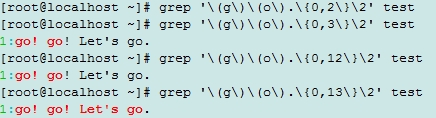
演示文本:go! go! Let‘s go.
grep演示
如不加括号,提示无效的向后引用

加括号后能正确匹配

把匹配范围缩小到g后的10个字符内

向后引用o这个单词
egrep演示
只要把"\"去掉
